智能感知与计算研究中心提出基于最优传输理论的影视换脸技术

科技改变影视生态
(影视剧换脸结果 素材来源自网络)
赋予机器类人创造力,使之能够自动理解和编辑影像是人工智能领域的前沿方向。
中科院自动化所智能感知与计算研究中心长期从事图像分析理解的信息理论基础研究,近期提出一种基于最优传输理论的影视换脸技术,着力于解决复杂光照和肤色条件下的人脸外观迁移问题,在挑战性的影视剧场景中实现了高效逼真的换脸效果。该技术能够部分缓解影视换脸人力成本高昂的问题,有望进一步推动影视娱乐领域的智能化程度。相关论文因可能会在深度伪造领域带来人工智能伦理影响,被NeurIPS2020大会条件接收,近日在获得6位专业审稿人(包含2位人工智能伦理专家)一致肯定后,被正式接收。
研究背景
影视换脸是指将原有影视作品中演员的人脸替换为另一名演员的人脸。为了实现逼真效果,除却身份信息外,替换后的人脸需保持和替换前人脸相同的属性,如光照和肤色等。传统的影视换脸需要专业人员手动逐帧编辑,费时费力且造价高昂。例如,电影《双子杀手》中将年轻时威尔·史密斯的人脸替换至影片中,短短4分钟的换脸戏份花费了长达九个月的后期制作时间。漫长的周期、高昂的费用严重制约了影视换脸的发展。
近年来兴起的生成机器学习模型给影视换脸带来了新颖且经济的解决思路。研究人员利用生成模型强大的学习和映射能力,实现人脸的自动替换。然而,当被替换影视中的人脸处于复杂的外观(光照、肤色)条件下时,当前基于生成模型的换脸技术难以取得令人满意的效果,出现各种“换脸后遗症”,如图1左边生成视频的面部出现忽明忽暗的色块。如何弥补生成视频和源视频之间的颜色属性差异,从而有效地实现换脸过程中的外观迁移成为亟待解决的问题。

图1. 复杂光照条件下,DeepFaceLab (左)和新方法(右)对比图
方法简述
为了解决上述问题,自动化所智能感知中心研究人员基于最优传输理论,将外观颜色迁移问题建模为一个最优传输问题,并提出外观最优传输模型Appearance Optimal Transport(AOT)。如图2所示,其采用重新打光生成器(Relighting)和混合分割判别器(Mix-and-Segment)分别在特征空间和像素空间同时求解传输计划。
特征空间上的迁移:提出一种神经最优传输计划估计模块(NOTPE),通过最小化隐空间特征的Wasserstein距离近似求解最优传输,实现外观在隐层空间的映射。这样一方面规避了传统最优传输方法的大规模计算问题,另一方面解决了图像之间运用最优传输时生成不连续且不真实图片的问题。同时该方法提取人脸相应的坐标以及法线信息,用于表示面部几何和光照,使得在特征空间上迁移的过程更为准确。
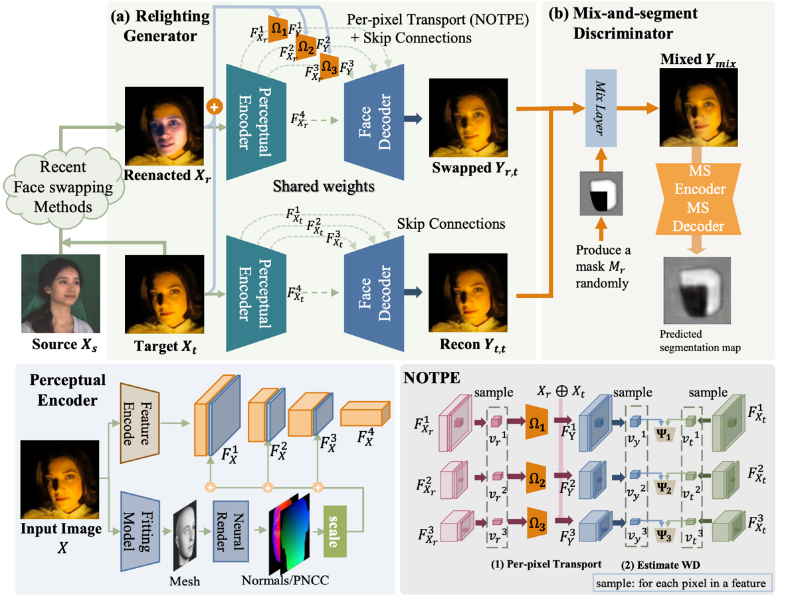
图2. AOT方法框架图
像素空间上的迁移:由于同一图像的特征空间和像素空间之间存在强关联性,该方法进一步探索如何在像素空间上减少外观差异。在传统的生成对抗网络中,判别器用于区分整张图像的真假,这样会使模型趋向于关注整体特征而忽略局部特征。为了实现更细粒度的图像生成,该方法利用换脸过程中的结构一致性,引入一种图像分割游戏。其将生成的假脸切块并和源图像随机混合,并使用一种新的判别器Mix-and-Segment(MSD)区分真假混合图像块中的真实部分。这种分割对抗机制能够促使生成图像在像素空间和目标图像尽可能相似,从而显著提升换脸效果。
应用验证
1.受控场景
在DPF-1.0数据集上,该方法与当前主流的换脸算法DFL和FSGAN的对比如图3所示。实验结果显示出该方法对光照变化的鲁棒性,能够在复杂光照条件下实现更加逼真的换脸效果。

图3. 受控场景下测试结果
2.现实场景
图4表明在现实影视场景中,该方法仍然展现出比传统方法更加卓越的性能优势。
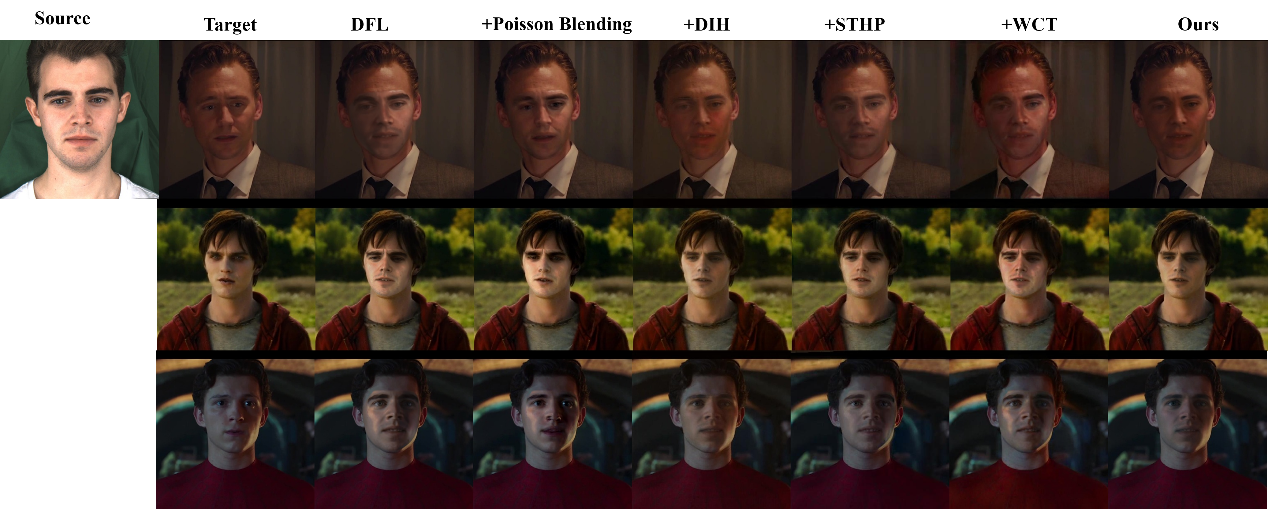
图4. 现实影视场景下测试结果
论文信息:
Hao Zhu*, Chaoyou Fu*, Qianyi Wu, Wayne Wu, Chen Qian, Ran He. AOT: Appearance Optimal Transport Based Identity Swapping for Forgery Detection. NeurIPS, 2020.
Ran He, Xiang Wu, Zhenan Sun, Tieniu Tan. Wasserstein CNN: Learning Invariant Features for NIR-VIS Face Recognition. IEEE Trans. Pattern Anal. Mach. Intell., 41(7): 1761-1773 (2019)