IEEE国际计算机视觉与模式识别会议(CVPR),是计算机视觉领域三大顶级会议之一。CVPR 2026计划于2026年6月3日至7日在美国科罗拉多州丹佛召开。本文介绍自动化所在本届会议上的录用论文成果(排序不分先后)。
Saliency-Guided Representation with Consistency Policy Learning for Visual Unsupervised Reinforcement Learning
论文作者:孙敬博,张启超,凃崧峻,方兴,郑宇鹏,李浩然,陈轲,赵冬斌
研究介绍:
零样本无监督强化学习(URL)为构建能够泛化到未知任务的通用智能体提供了有前景的方向。在现有方法中,后继表示(SR)凭借其理论基础以及在低维环境中的有效性,成为重要研究范式。然而,SR 方法在高维视觉环境中的扩展能力仍然受限。通过系统实验分析,我们发现 SR 在视觉 URL 场景中存在两个关键问题:(1) 其训练目标容易学习到与环境动态无关的次优表征,导致后继度量估计不准确,从而削弱泛化能力;(2) 不充分的表征进一步限制了策略对多模态技能条件动作分布的建模能力,影响技能可控性。为解决上述问题,我们提出显著性引导表示与一致性策略学习(SRCP)框架。SRCP 通过引入显著性引导的动态表征任务,将表示学习与后继训练解耦,从而学习动力学相关表征并提升后继度量准确率。同时,SRCP引入URL特定的无分类器引导的一致性策略学习,以增强技能条件策略的多样性与可控性。在ExORL基准上的大量实验表明,SRCP在视觉URL场景下实现了最优的零样本泛化性能,并可兼容多种 SR 方法。
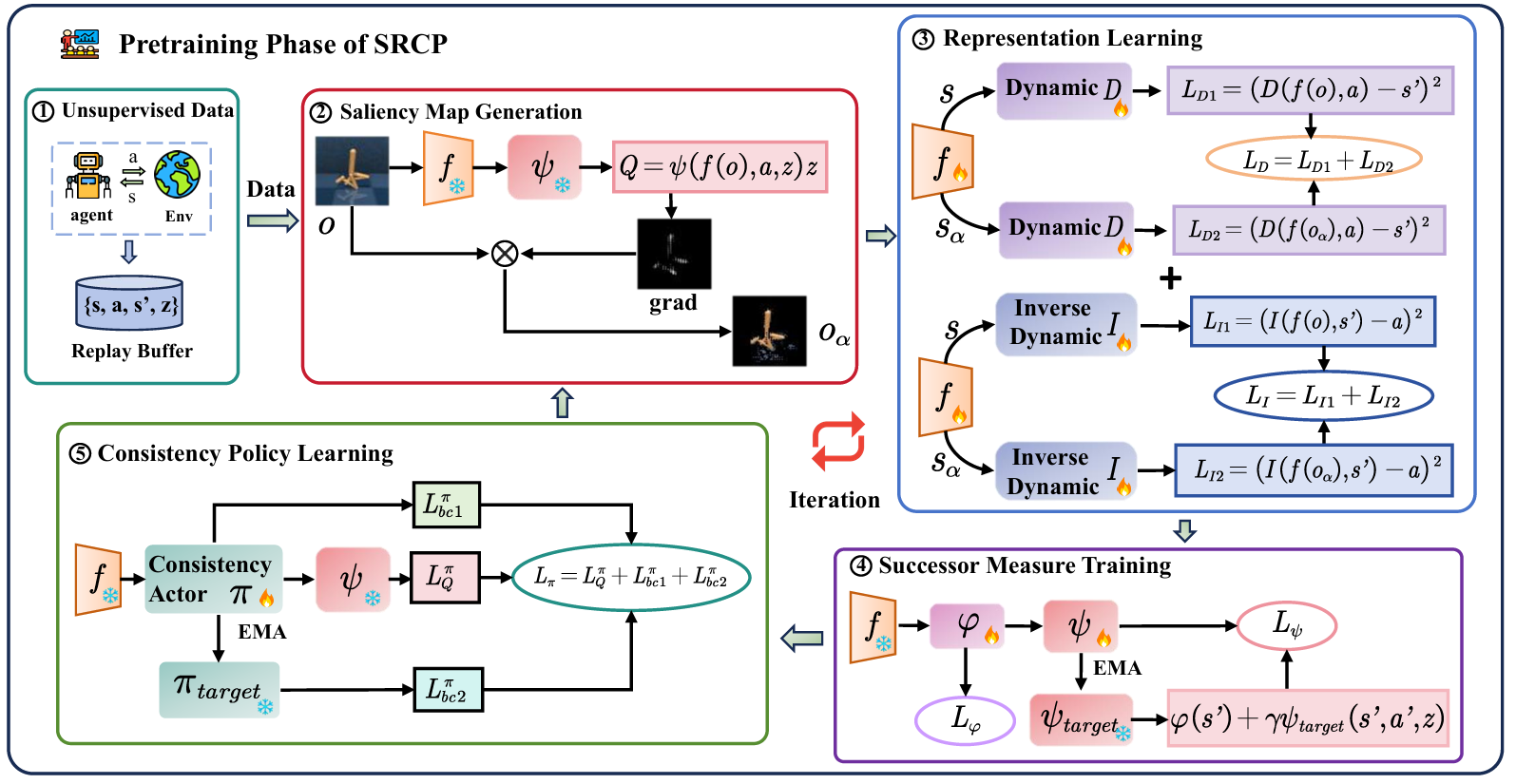
SRCP 预训练框架。SRCP 首先利用无监督数据生成显著性图,引导显著性相关的动态表征。所得到的编码器在后继测度训练与一致性策略学习之间共享,从而实现更加准确的后继测度建模。进一步SRCP利用一致性策略实现更具多样性与控制能力的策略行为,进一步提升泛化能力。
2. MeanFuser:基于 MeanFlow 的快速单步多模态轨迹生成与自适应重构的端到端自动驾驶方法
MeanFuser: Fast One-Step Multi-Modal Trajectory Generation and Adaptive Reconstruction via MeanFlow for End-to-End Autonomous Driving
论文作者:王君礼,刘学义,邢泽斌,郑一楠,李鹏飞,李广,马昆,陈光,叶航军,夏中谱,陈龙,张启超
研究介绍:
生成模型在轨迹规划中展现出巨大潜力。近期研究表明,基于锚点引导的生成方法能够有效刻画驾驶行为不确定性并提升整体性能。然而,这类方法依赖离散锚点词汇表,并要求其在测试阶段充分覆盖轨迹分布以保证鲁棒性,从而在词汇规模与模型性能之间引入内在权衡。为突破该限制,我们提出端到端自动驾驶方法 MeanFuser,在提升效率的同时增强鲁棒性。具体而言,MeanFuser 引入高斯混合噪声(GMN)引导生成采样,实现对轨迹空间的连续建模,从根本上消除对离散锚点词汇表的依赖。进一步地,我们将 MeanFlow Identity引入端到端规划框架,通过建模 GMN 与轨迹分布之间的平均速度场,替代传统流匹配中的瞬时速度场,有效避免 ODE 求解带来的数值误差,并显著加速推理过程。此外,我们设计轻量化自适应重构模块(ARM),使模型能够通过注意力机制在采样候选中进行隐式选择或重构新轨迹。在 NAVSIM 闭环基准上的实验结果表明,MeanFuser 在无需额外监督信号的情况下取得了优异性能,同时具备卓越的推理效率。
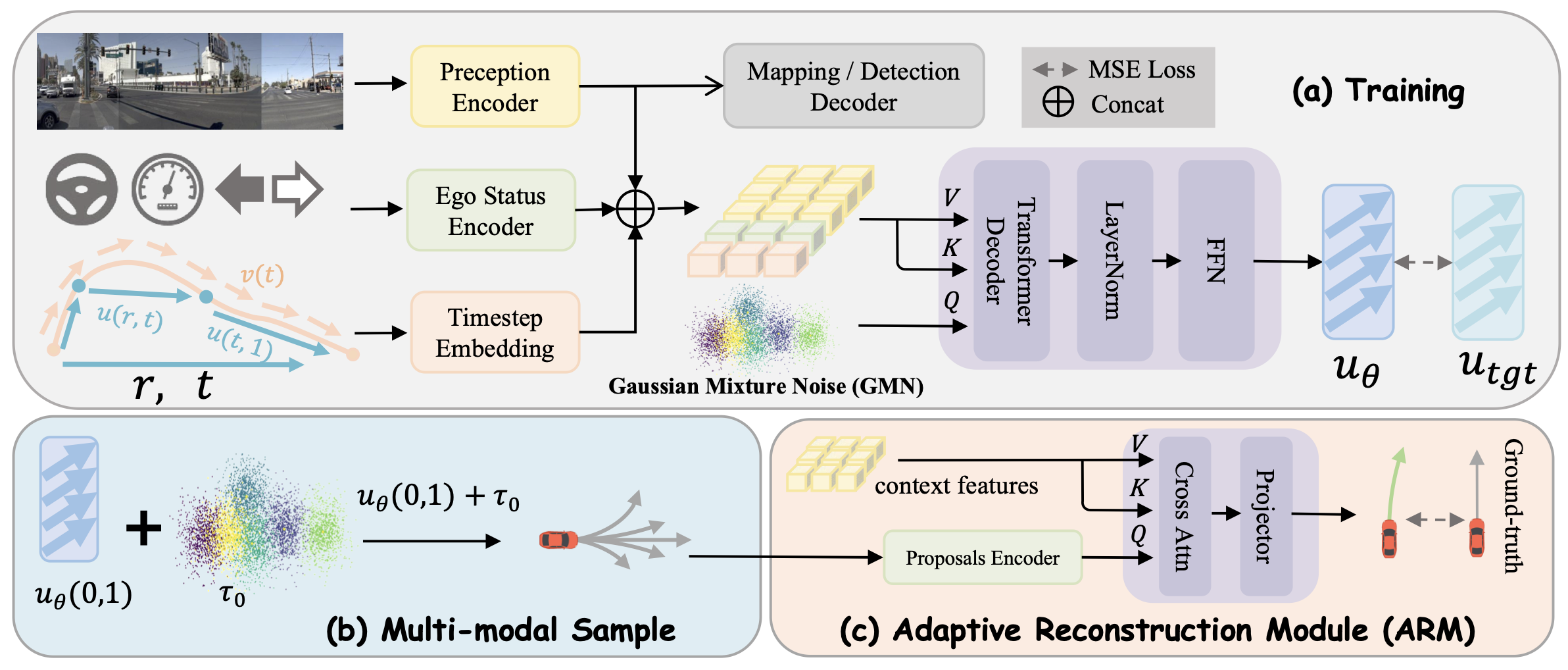
MeanFuser 整体架构。训练阶段: 在训练过程中,图像与自车状态首先被编码为上下文特征,同时引入来自地图构建与目标检测任务的辅助监督信号。模型在这些上下文特征的条件下,学习时间区间 r与 t之间的平均速度场。多模态采样: 噪声样本从高斯混合噪声中采样,并通过单步采样公式生成多样化的多模态轨迹。自适应重构模块: 采样得到的多模态轨迹首先被编码,并通过交叉注意力机制与上下文特征进行融合,随后输出最终的规划轨迹。
3.基于动态分词关系 Transformer 的工程图纸端到端超关系信息抽取
End-to-End Hyper-Relational Information Extraction for Engineering Diagrams via Dynamically Tokenized Relation Transformer
研究介绍:
工程图纸是工业场景中技术信息的核心载体。工业领域对图纸数字化的迫切需求,推动了相关研究领域的快速发展。然而,现有研究仍存在以下不足:首先,符号、线条与文字的检测通常依赖多个独立模型,导致流程繁琐冗余;第二,高分辨率图纸往往会给现有模型带来过高的计算开销;第三,仅基于目标检测的解析框架只能定位构件位置,无法捕捉构件间的拓扑连接语义与结构化知识,对工业实际应用的支撑有限。针对上述问题,本文提出一种基于动态分块关系 Transformer(DTRT) 的端到端信息抽取框架。该框架可动态减少输入图像token数量、过滤冗余信息,并高效抽取结构化知识以构建超关系知识图谱。我们在管道及仪表流程图(P&ID) 和电气图纸(ED) 上开展了实验验证:前者广泛应用于化工工程企业,后者用于描述电路系统。DTRT 在 P&ID 上达到 94.84% 的 R@1000 精度,在电气图纸上达到 92.52% 的 R@200 精度,同时显著降低了计算成本。
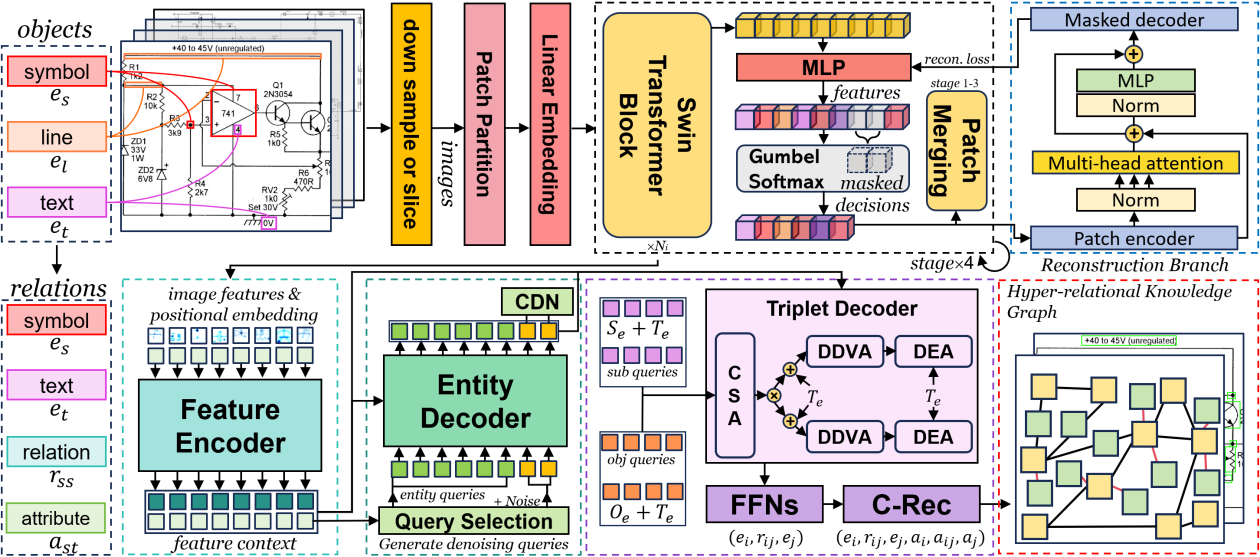
DTRT 的工作流程:首先对图纸进行下采样或切片,再经由动态分块视觉主干网络处理。网络中嵌入评分器以裁剪无用的视觉 Token,其训练由仅在训练阶段激活的重建分支辅助完成。随后,经裁剪后的 Token 由引入对比去噪锚点与查询选择改进的单阶段关系 Transformer 处理,最终生成工程图纸的超关系知识图谱。
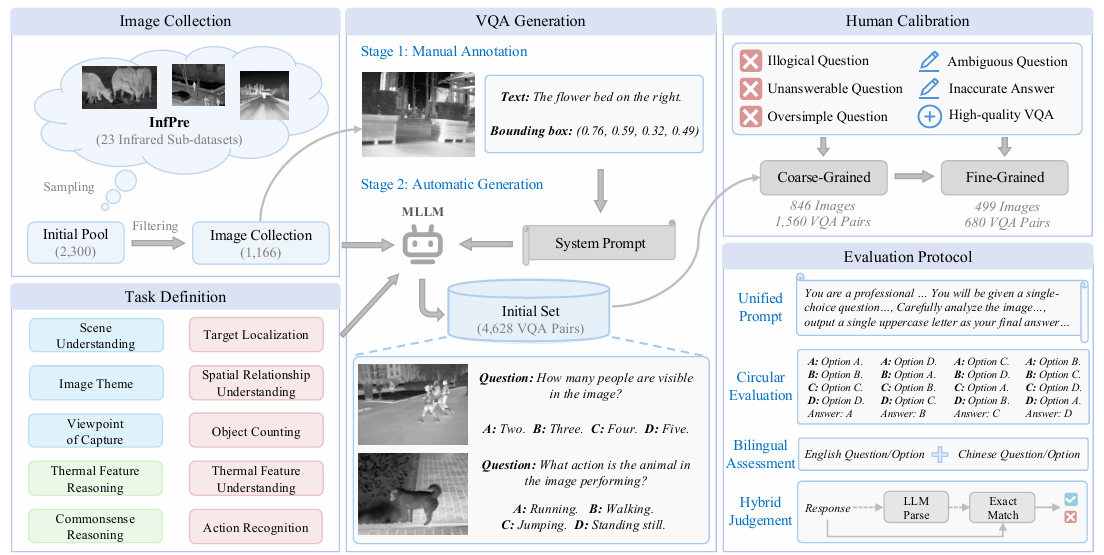
4. SAM2Text:面向视频场景文本分割的自提示与多分辨率解码框架
SAM2Text: Towards Prompt-Free and Multi-Resolution Video Scene Text Segmentation
研究介绍:
视频中的场景文本作为高层语义线索,对视频内容理解、跨模态检索等下游任务至关重要。视频场景文本分割旨在像素级别精确且稳定地跟踪视频序列中的每一个文本实例,是该领域的基础性关键任务。然而,现有方法在处理视频文本时仍面临三大核心挑战:性能瓶颈——在复杂真实场景下,模型难以泛化至多样的字体、布局及背景干扰;流式处理局限——多数先进模型专为图像级设计,无法以流式方式高效处理连续视频帧;时序稳定性不足——缺乏有效机制抑制分割结果的闪烁与抖动,难以满足实际应用对时序一致性的严苛要求。
针对上述挑战,本文提出了一种基于SAM2的创新框架SAM2Text。该框架通过三大核心设计系统性地解决问题:首先,采用LoRA高效微调策略适配图像编码器,并集成自提示模块,使模型能够自主生成文本感知的提示,实现无需外部提示的自动化分割;其次,在解码器中引入多分辨率上采样分支(512×512和1024×1024),生成高保真、保留精细笔画结构的文本掩码;最后,通过结合短期记忆与Top-K选择策略增强记忆机制,确保长视频中分割结果的时空一致性和稳定性。
此外,针对视频场景文本分割领域数据匮乏的瓶颈,本文贡献了两个高质量数据集:包含1,410个合成视频片段的STS-SynthV,以及包含660个精心标注的真实视频序列的STS-RealV。实验表明,SAM2Text在多个视频和图像场景文本分割基准上均达到了最先进的性能,为视频文本理解与分析奠定了坚实基础。
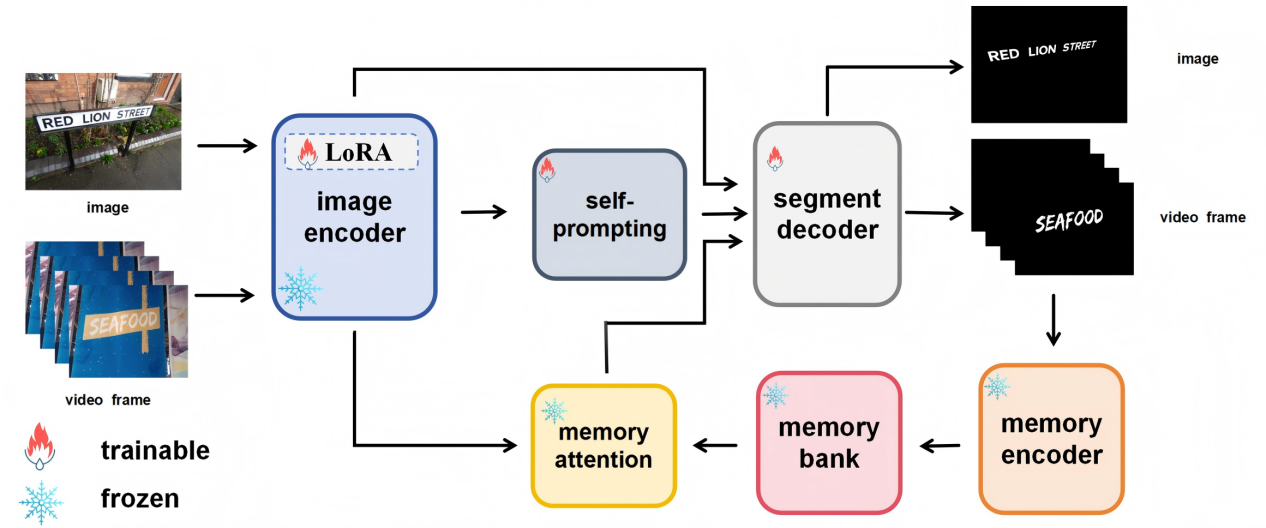
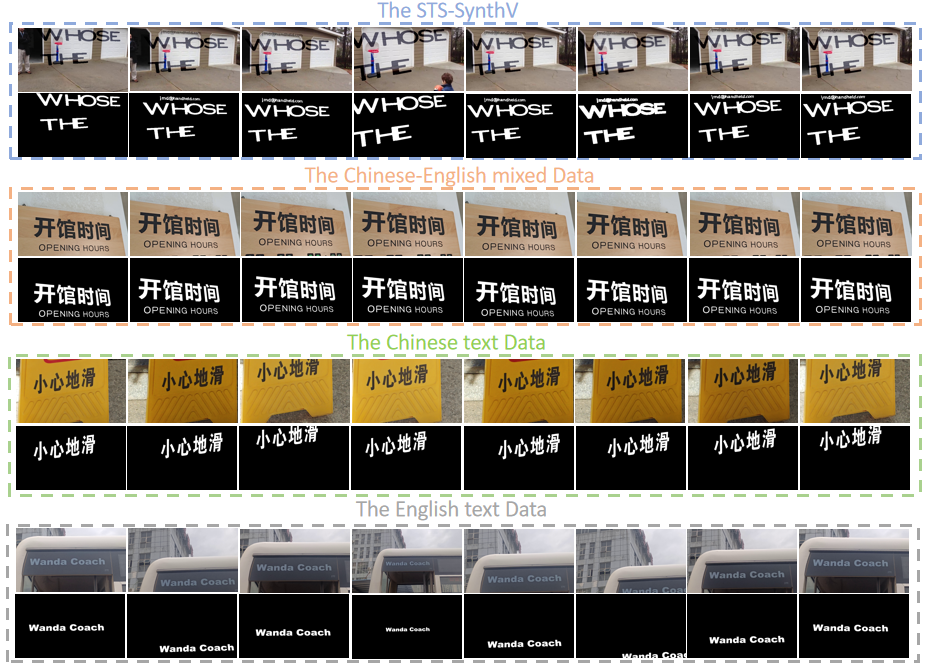
图2. 数据集的示例帧和标签:顶行展示了合成的STS-SynthV数据集;后续行则呈现了包含中文、中英混合以及英文文本的真实世界子集。
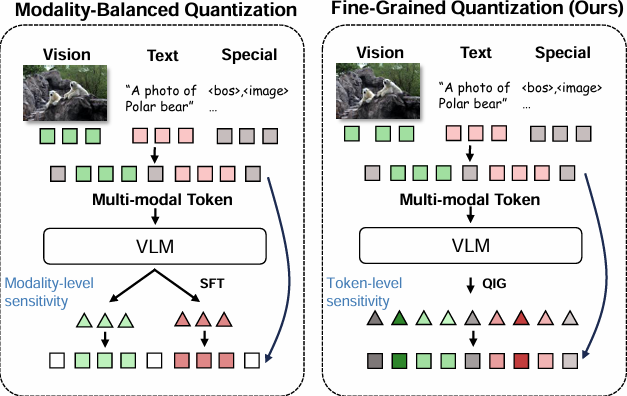
Fine-Grained Post-Training Quantization for Large Vision Language Models with Quantization-Aware Integrated Gradients
论文作者:向子维,曾繁虎,方宏坚,王瑞琪,陈仁兴,朱亚男,陈懿,杨沛沛,张煦尧
研究介绍:
大型视觉语言模型(LVLMs)虽在多模态任务中表现卓越,但其巨大的计算与内存开销阻碍了实际部署。现有的后训练量化(PTQ)方法通常仅在“模态级别”(仅区分视觉和文本)衡量敏感度,忽略了同一模态内不同token之间也存在复杂的交互差异,导致量化精度受损。本研究受可解释性思想的启发,提出了一种名为量化感知积分梯度(Quantization-Aware Integrated Gradients, QIG)的细粒度量化策略。该方法通过计算从量化参考输入到实际输入的积分梯度,将敏感度分析的粒度从“模态级”精细推进至“Token级”,能够定量评估每个token对量化误差的具体贡献。结合鲁棒的统计截断机制,QIG能精准识别并保护对量化噪声最敏感的关键token。在LLaVA-onevision、InternVL等多个主流模型上的实验表明,该方法在W3A8等低比特设置下,将量化模型与全精度模型的性能差距缩小至1.33%以内,且几乎不增加推理延迟,为LVLM的高效部署提供了新的解决方案。
FACE: A Face-based Autoregressive Representation for High-Fidelity and Efficient Mesh Generation
论文作者:王瀚霄,郭元晨,刘应天,邹子昕,张彪,全卫泽,梁鼎,曹炎培,严冬明
研究介绍:
传统的3D网格自回归生成模型由于将网格展平为冗长的顶点坐标序列,导致计算成本极高,阻碍了高保真几何体的合成。为突破这一算力瓶颈,本文提出了 FACE,一种新颖的自回归自编码器(ARAE)框架。FACE 的核心创新在于转换了操作的语义层级,提出了“一面一Token”的策略。它将网格的基础构建块——三角形面(Face)——直接作为单一、统一的 Token 进行处理。这一设计将序列长度大幅缩减至原来的九分之一,实现了0.11的极致压缩比,将此前的行业最高效率翻了一倍。这种效率的飞跃并未牺牲生成质量。通过与强大的 VecSet 编码器结合,FACE 在标准测试中达到了最先进(SOTA)的重建质量。此外,其学习到的潜在空间极具通用性,能够通过训练潜在扩散模型,实现高保真度的单张图像到3D网格的直接生成。FACE 提供了一种简单、可扩展且强大的新范式,大幅降低了高质量结构化3D内容创作的门槛。
FACE算法生成高保真网格。我们提出了一种新型自回归自编码器(ARAE)FACE,它采用了一种新的网格压缩策略。该范式使用显著缩短的序列来表示网格,在实现高质量三维几何体的同时,实现了最先进的效率。
7.时间表征增强(TRE):学习遗忘主导模式以获得更具区分性的脉冲特征
Temporal Representation Enhancement (TRE): Learning to Forget Dominant Patterns for More Discriminative Spiking Features
研究介绍:
脉冲神经网络(SNN)能够自然地处理跨多个时间步的视觉输入,从而提供丰富的时序动态信息和高效的计算能力。然而,训练中常用的时间不变监督往往会强化跨时间步的相同主导响应模式,导致冗余表征并限制时间区分能力。为了克服这一限制,我们引入了时间表征增强(TRE),这是一种新颖的“学习遗忘”范式,旨在鼓励更多样化和互补的时间表征。TRE通过类别特定的贡献估计和时间累积来识别高贡献语义模式,并使用动态调制策略选择性地抑制它们。通过将模型的注意力重新定向到其他同样具有信息量的语义线索,TRE促进了跨时间步互补特征的学习。这种方法不仅增强了SNN的时间区分能力,而且通过利用更丰富的语义信息,实现了更有效的多时间步学习。在静态图像数据集和动态神经形态数据集上的大量实验表明,TRE 能够持续提高不同 SNN 主干网络的分类准确率和特征多样性。
SRA-Det: Learning Omni-Grained Open-Vocabulary Detection Beyond Category Names
研究介绍:
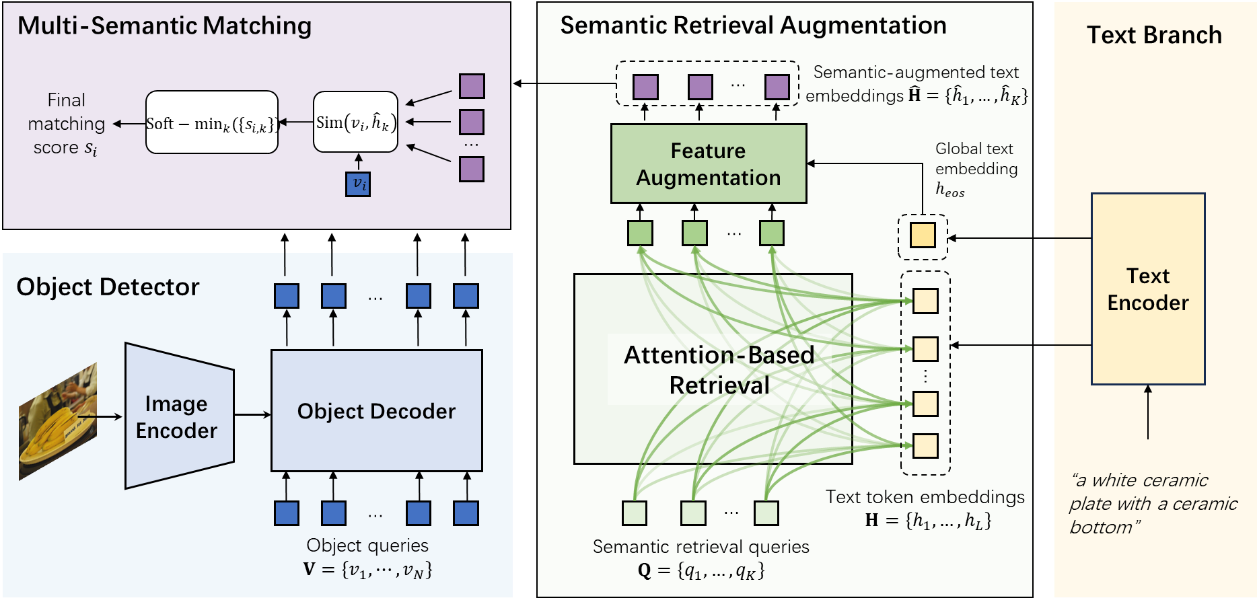
本工作针对开放词汇目标检测(Open-Vocabulary Detection, OVD)在细粒度理解方面的不足,提出了一种语义检索增强检测器 SRA-Det。现有OVD方法通常将整段文本压缩为单一嵌入向量,容易忽略颜色、材质、形状等关键属性信息,导致在细粒度场景下性能显著下降。为解决该问题,本文在模型与数据两个层面进行创新:在模型方面,设计了语义检索增强模块,通过多查询注意力机制从文本token中提取多个语义子空间表示,并采用可微soft-min匹配策略实现类似“逻辑与”的多属性一致性约束,从而显著提升细粒度识别能力;在数据方面,构建了自动属性增强数据流水线,利用大语言模型生成类别相关视觉属性,并结合双重CLIP相似度验证实现实例级属性标注,大规模提升属性监督密度。在Swin-T骨干下,方法在FG-OVD零样本达到54.9 mAP,在LVIS minival零样本取得40.4 AP,兼顾细粒度与通用开放检测能力。
Beyond Semantic Search: Towards Referential Anchoring in Composed Image Retrieval
论文作者:杨宇鑫,周熠楠,陈禹昕,张子琦,马宗扬,原春锋,李兵,高君,胡卫明
组合图像检索(CIR)任务能够支持灵活的多模态查询,将参考图像与修改文本相结合。然而,组合图像检索侧重于语义匹配,难以可靠地在不同情境中检索出用户指定的特定实例。在实际应用中,相较于广泛的语义匹配,实例保真度往往更为重要。在本研究中,我们提出了对象锚定的组合图像检索(OACIR),这是一种新颖的细粒度检索任务,要求严格保证实例级别的一致性。我们构建了OACIRR,这是首个大规模、多领域的基准测试,包含超过16万个四元组以及四个具有挑战性的候选图集,这些图集中加入了具有困难负实例干扰的负样本。每个四元组都在组合查询中添加一个边界框,以在参考图像中直观地锚定对象,从而提供一种精确且灵活的方式来提供实例信息。此外,我们提出了AdaFocal框架,其包含一个具备情境感知的注意力调节模块,该模块能够自适应地增强指定实例区域内的注意力,从而动态地在锚定实例与更广泛的组合上下文中平衡焦点。大量的实验表明,AdaFocal明显优于现有的组合检索模型,特别是在保持实例一致的准确性方面表现更优,为这一具有挑战性的新任务建立了一个可靠的基准,并为更具灵活性、基于实例的检索系统开辟了新的方向。
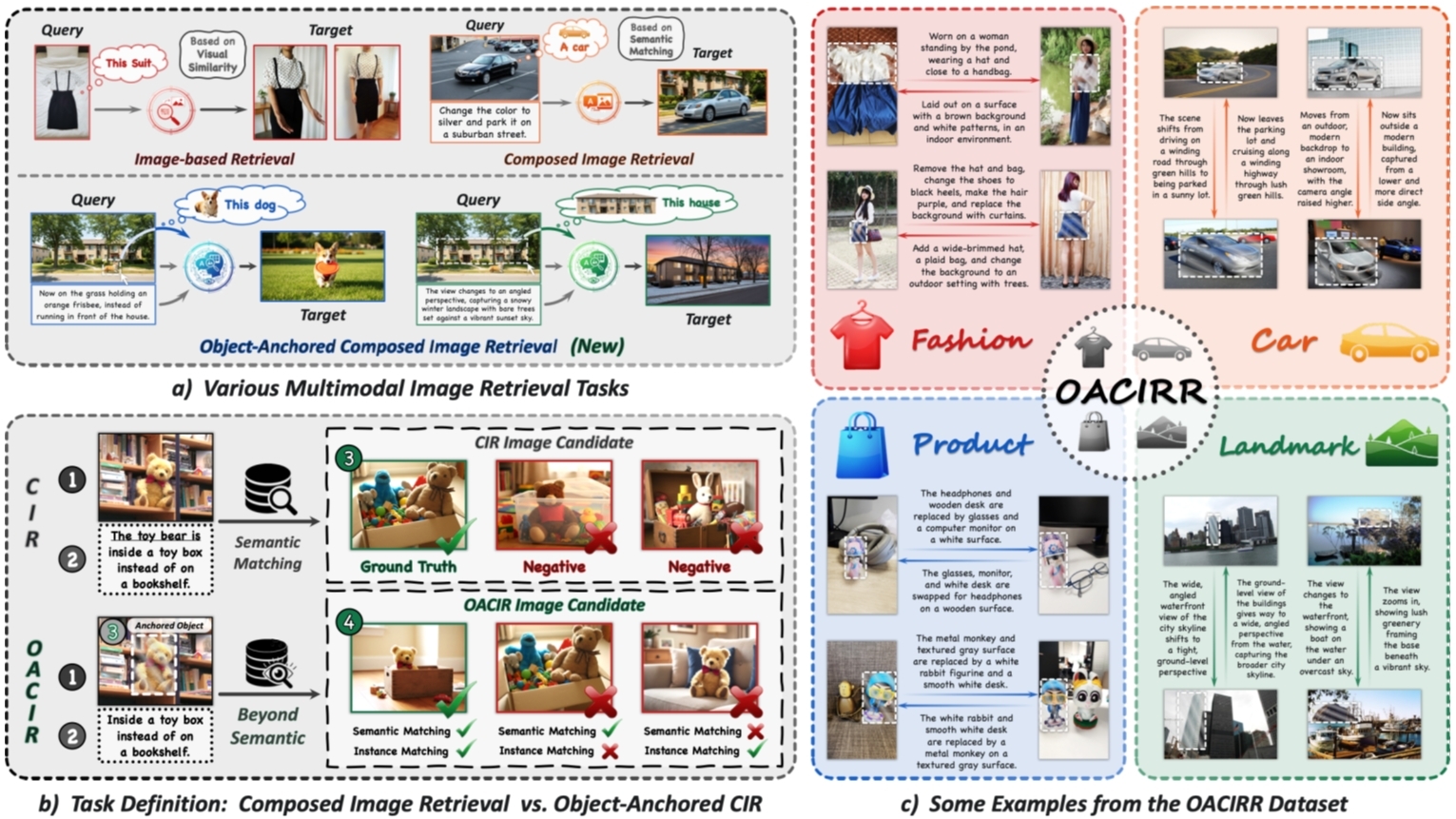
对象锚定的组合图像检索(OACIR)任务概览图
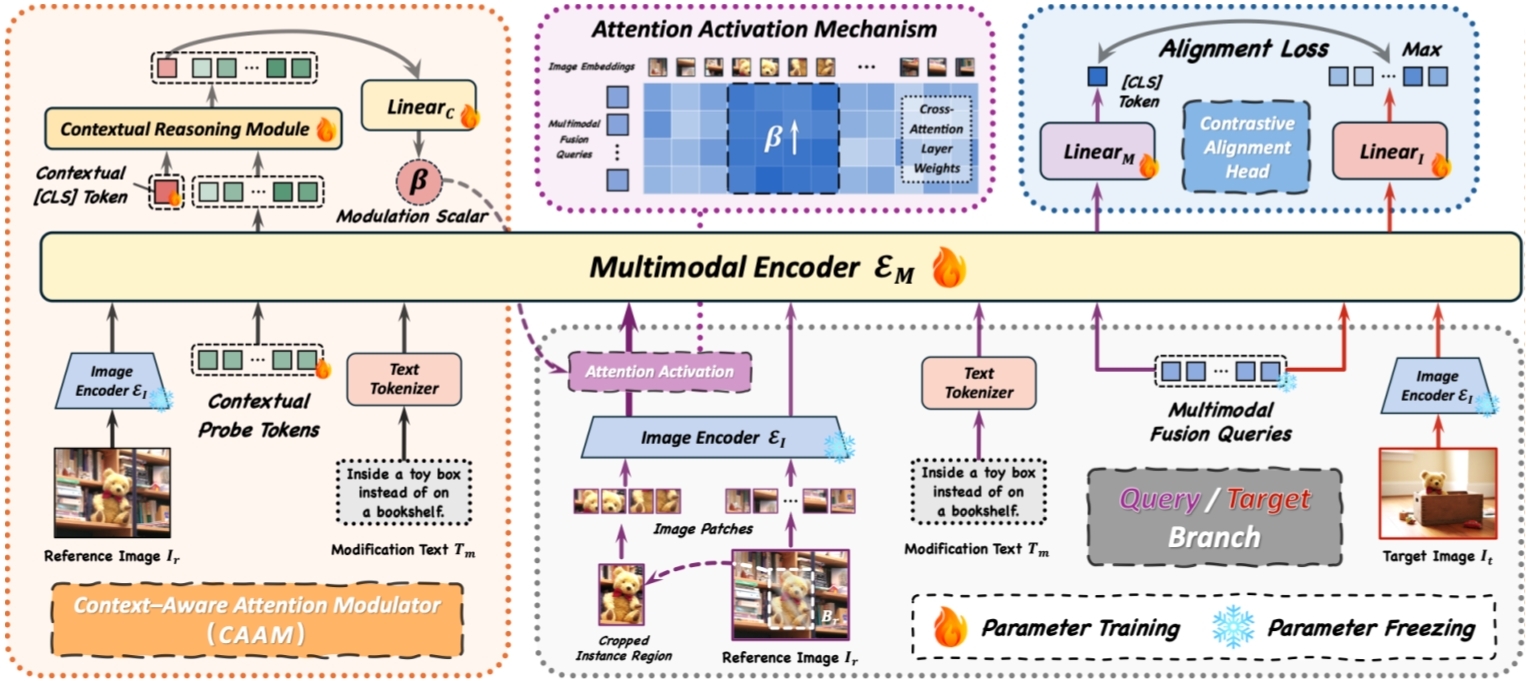
AdaFocal框架示意图
Simple, Efficient, and Adaptive Multimodal Tracker
研究介绍:
参数高效微调在多模态目标追踪中的应用揭示出一个值得关注的趋势:近年来性能提升往往以计算量和参数规模的显著增加为代价,从而削弱了该范式所承诺的效率优势。为此,本文重新审视现有多模态追踪方法的局限,并提出 SEATrack--一种简单、高效且自适应的双流多模态追踪框架,从两个互补角度缓解性能与效率之间的矛盾。
首先,我们强调跨模态匹配响应对齐这一尚未被充分探索但至关重要的因素,并指出其是打破上述困境的关键。我们发现现有双流方法中的模态特定偏差会产生相互冲突的匹配注意力图,进而阻碍有效的跨模态联合表征学习。为此,我们提出 AMG-LoRA,将低秩适配(LoRA)与自适应互引导机制(Adaptive Mutual Guidance, AMG)结合,在跨模态之间动态优化并对齐注意力图。在此基础上,我们进一步突破传统局部融合范式,引入分层混合专家结构(Hierarchical Mixture of Experts, HMoE)以实现高效的全局关系建模,从而在跨模态融合中更好地平衡表达能力与计算效率。
借助上述创新,SEATrack 在 RGB-T、RGB-D 和 RGB-E追踪任务中,在性能与效率的平衡方面相较于当前最先进的方法取得了显著进展。
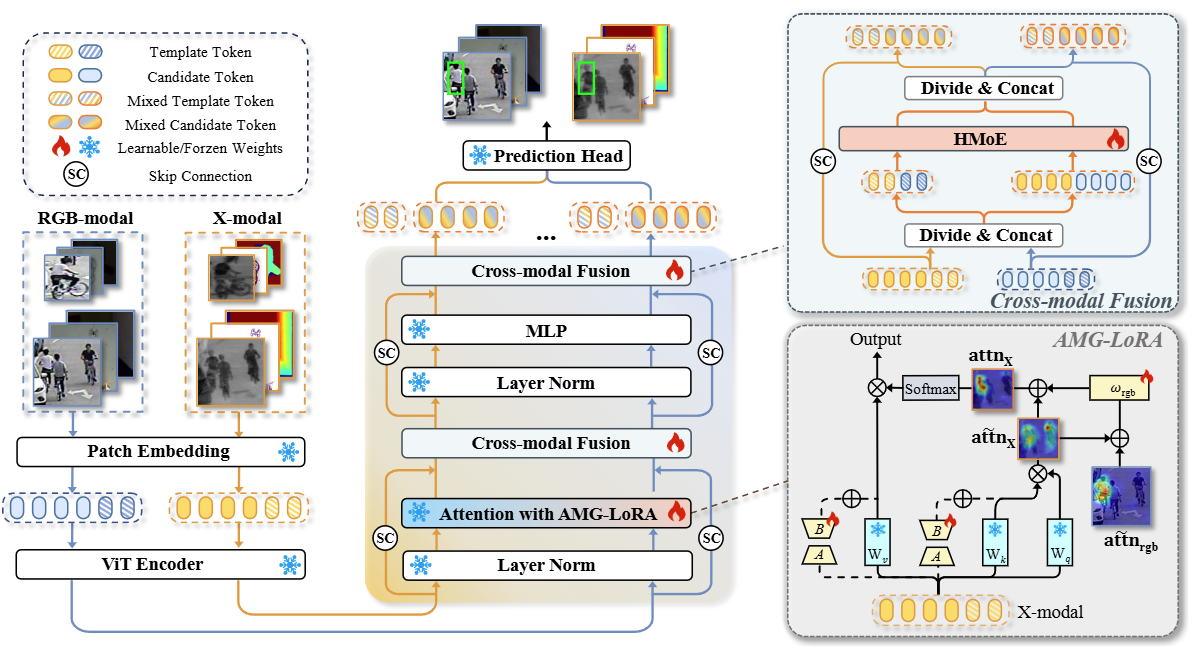
图1. 整体框架图,其跨模态交互遵循“先对齐、后融合”的设计准则
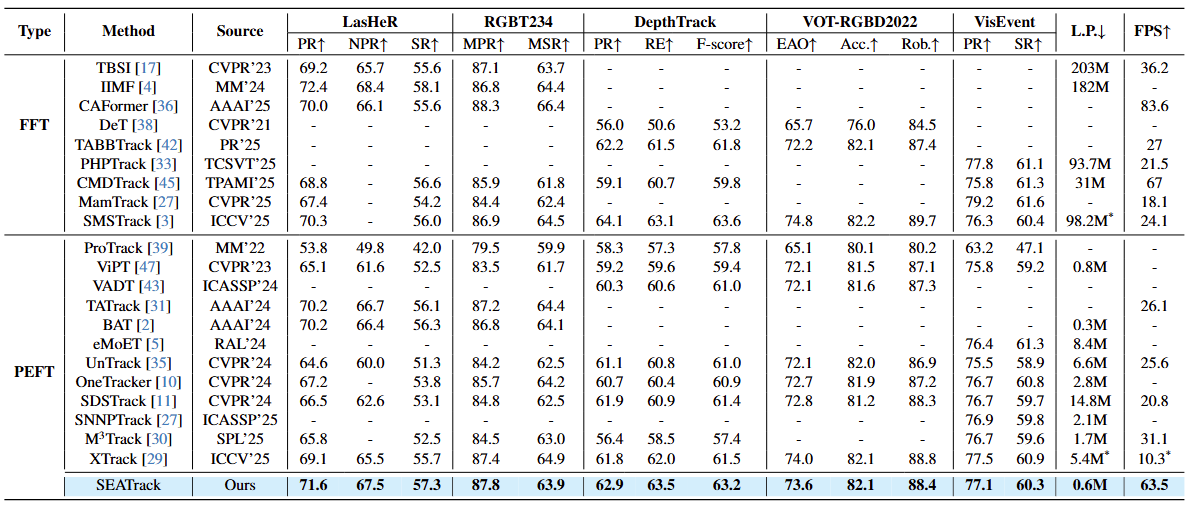
图2. 性能-效率对比图,SEATrack以更少的参数量取得了更好的整体性能与推理速度
11. Mesh-Pro: 面向艺术家风格四边面Mesh生成的异步优势引导排序偏好优化
Mesh-Pro: Asynchronous Advantage-guided Ranking Preference Optimization for Artist-style Quadrilateral Mesh Generation
研究介绍:
强化学习在文本与图像生成领域已取得显著成功,但其在 3D 生成领域的潜力仍未被充分发掘。现有的研究通常依赖于离线的直接偏好优化(如DPO),存在训练效率低和泛化能力有限的不足。在本文中,我们旨在同时提升强化学习在 3D mesh生成中的训练效率与生成质量。具体地:(1)设计了首个专为提升 3D mesh生成后训练(Post-training)效率的异步在线强化学习框架,其训练速度较同步强化学习提高了 3.75 倍;(2)提出了一种强化学习算法——优势引导排序偏好优化(Advantage-guided Ranking Preference Optimization, ARPO),相较于目前专为 3D mesh生成设计的其他强化学习算法(如DPO与GRPO等),ARPO在训练效率与泛化能力之间实现了更优的权衡;(3)基于异步ARPO,提出了Mesh-Pro方法。针对mesh表征额外引入了一种对角感知混合三边-四边面分词技术(Diagonal-aware mixed tri-quad tokenization),并采用基于射线的奖励函数(Ray-based reward)以确保几何完整性。Mesh-Pro 在艺术家风格(Artistic)与dense mesh生成上均达到了SOTA的性能。
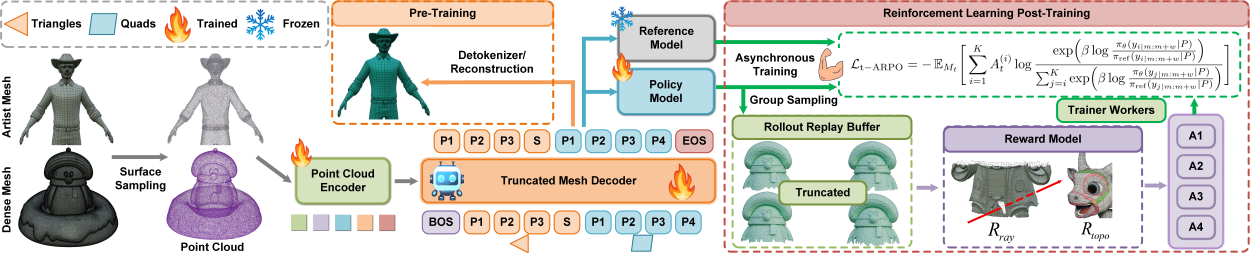
图1. Mesh-Pro框架图

12. MORE-STEM:长短期记忆与时空一致建模的查询驱动点云理解方法
MORE-STEM: Long-Short MemOry REcall and Spatio-TEmporal Consistency Model for Query-Driven 3D/4D Point Cloud Segmentation
研究介绍:
当前基于查询的3D理解方法仅适用于静态点云,限制了其对动态场景的推理能力。为弥补这一缺口,我们提出MORE-STEM统一框架,该框架整合了长短期记忆检索与时空一致性模型,用于查询驱动的3D/4D点云分割。该框架首先引入跨帧文本-视觉对齐模块,在语言查询与动态三维特征间建立精细化、时间感知对应关系。在此基础上,时空一致性模型模块通过运动感知机制确保连续帧间的连贯性,实现稳定且时间一致的分割结果。长短时记忆召回模块通过分层记忆机制平衡长期语义记忆与短期适应性,进一步增强跨场景推理能力。我们同时构建了基于时序对齐、运动中心文本注释的全新户外3D/4D指令分割基准数据集。实验表明,MORE-STEM在多项3D/4D理解任务中均达到当前最先进水平。
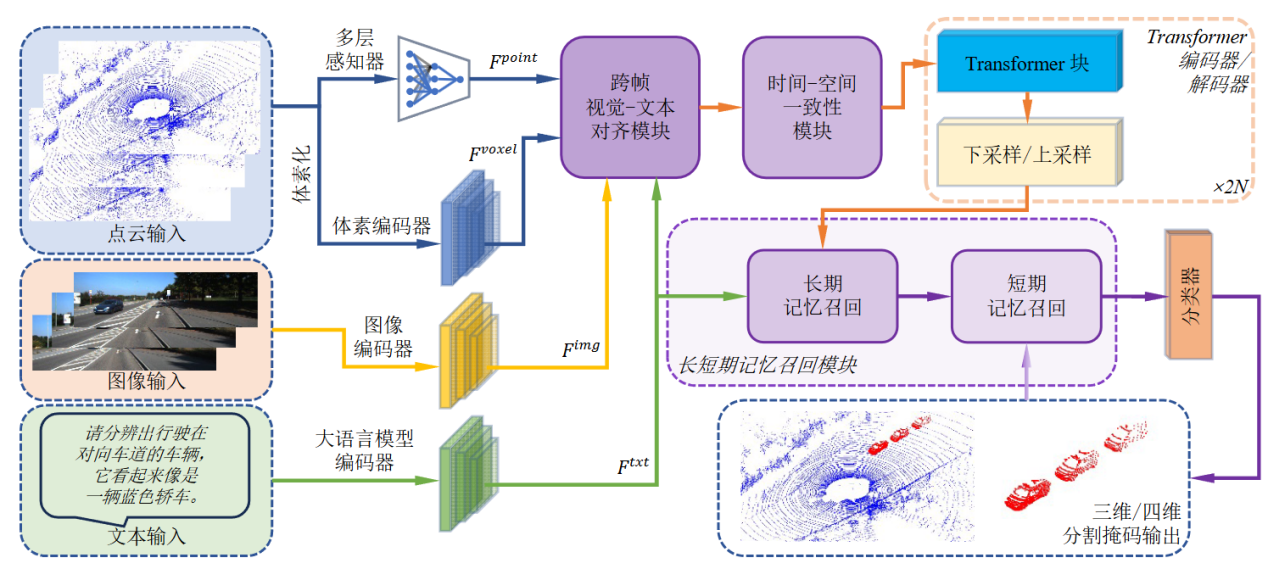
13. CC-VQA:面向基于知识的视觉问答中知识冲突缓解的冲突与相关性感知方法
CC-VQA: Conflict- and Correlation-Aware Method for Mitigating Knowledge Conflict in Knowledge-Based Visual Question Answering
论文作者:洪宇洋、顾佳琦、楼雨京、樊鲁斌、杨奇、王颖、丁昆、吴岳、向世明、叶杰平
研究介绍:
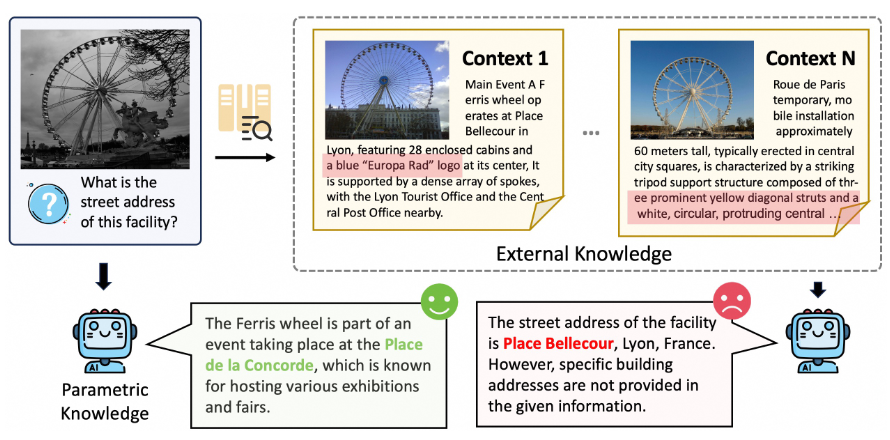
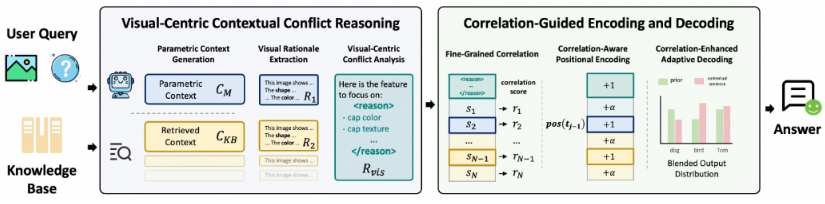
基于知识的视觉问答(KB-VQA)在处理知识密集型任务时潜力巨大,但面临模型静态参数知识与动态检索信息之间的冲突。现有方法大多借鉴语言领域,忽视视觉信息,且易受冗余上下文干扰,难以精准缓解该冲突。为此,提出 CC-VQA——一种无需训练的冲突与相关性感知新方法。包含两大创新模块:一是“以视觉为中心的上下文冲突推理”,深入分析内外知识的视觉语义冲突;二是“相关性引导的编码与解码”,压缩低相关性陈述,形成自适应解码优化输出。在E-VQA、InfoSeek 及 OK-VQA 等多个基准测试中,CC-VQA 均达到业界领先(SOTA)性能,准确率绝对提升达 3.3% 至 6.4%。所提CC-VQA可望为 KB-VQA 领域的知识冲突问题提供一种高效的解决方案。
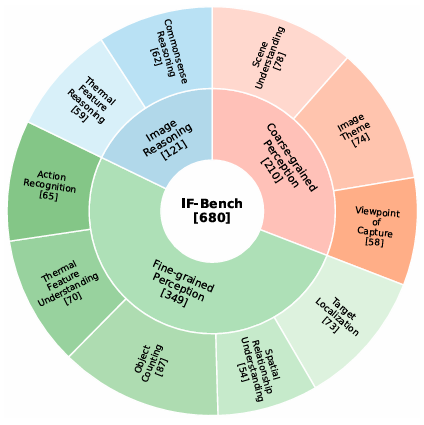
14. IF-Bench:基于生成式视觉提示的红外图像多模态大语言模型基准测试与增强方法
IF-Bench: Benchmarking and Enhancing MLLMs for Infrared Images with Generative Visual Prompting
论文作者:张涛、 洪宇洋、夏阳、丁昆、张泽宇、王颖、向世明、潘春洪
研究介绍:
近期,多模态大语言模型(MLLMs)在多项基准测试中表现卓越,但其对红外图像的理解能力仍是研究空白。为此,本文首次推出高质量基准IF-Bench,覆盖红外图像理解的10个核心维度。 基于该基准,系统评估了40余款开源与闭源MLLMs,建立了循环评估、双语评测与混合判断的新策略,显著提升结果可靠性。该项研究深入揭示了模型规模、架构及推理范式对红外理解的影响。此外,提出无需训练的GenViP方法,借助先进图像编辑模型将红外图像转化为语义与空间对齐的RGB图像,有效缓解域分布偏移。实验表明,GenViP在多种MLLMs上均带来显著性能提升。
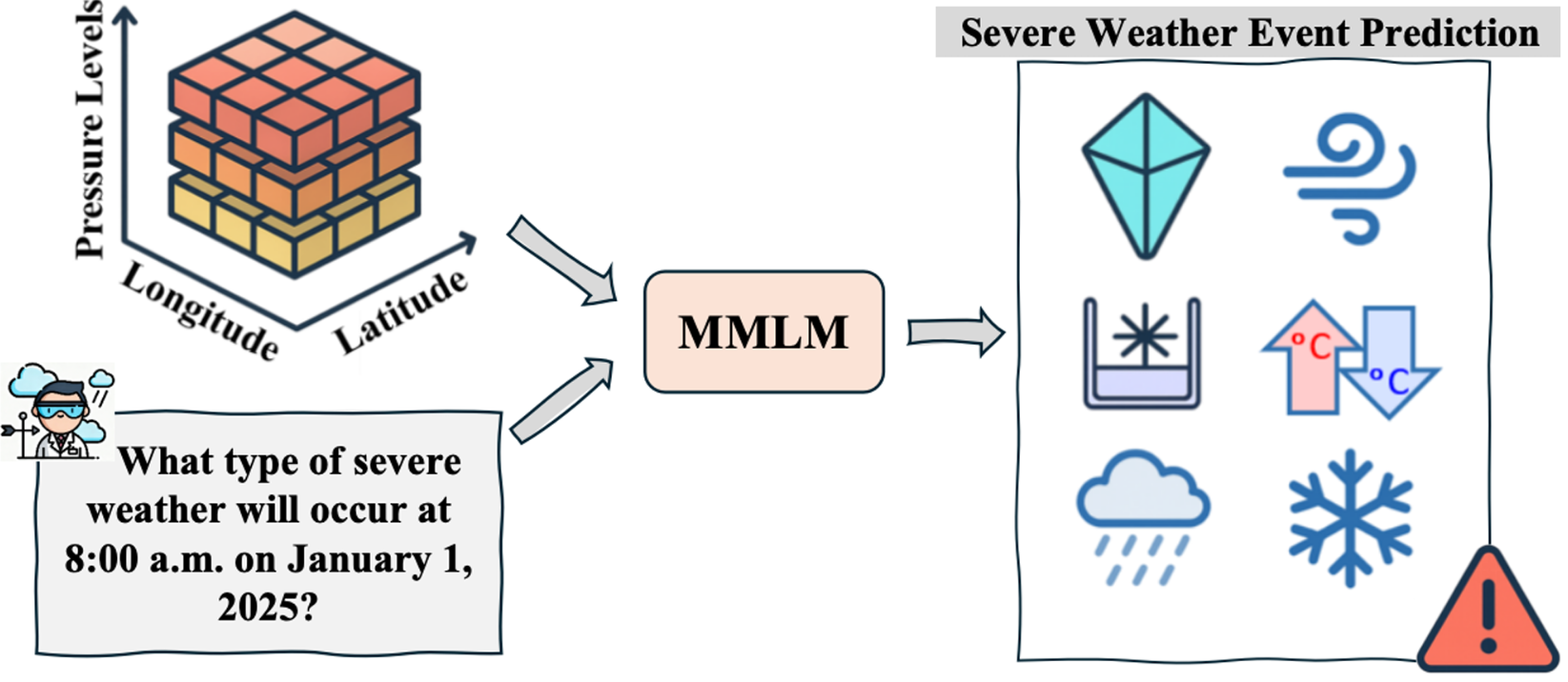
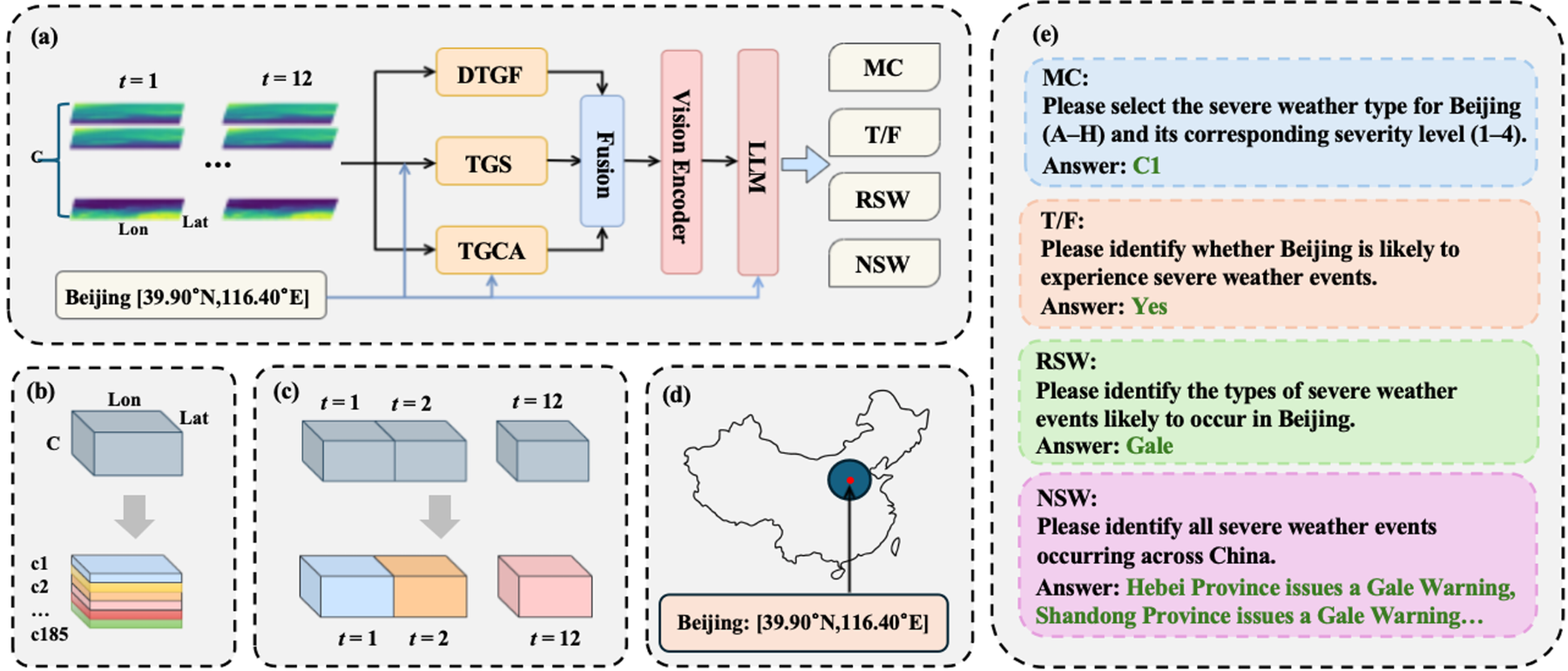
15. MeteorPred:面向极端天气预测的气象多模态大模型与基准数据集构建
MeteorPred: A Meteorological Multimodal Large Model and Dataset for Severe Weather Event Prediction
论文作者:唐硕、徐健、张家栋、陈懿、靳淇兆、申领东、刘成林、向世明
研究介绍:
及时准确的极端天气预测对早期预警与决策至关重要。传统预测高度依赖耗时的专家人工解读。当前,端到端的“AI气象台”已成为发展趋势,但仍面临三大挑战:极端样本稀缺、高维气象数据与文本预警匹配度低,且现有多模态模型难以捕捉复杂的高维时空依赖。为此,提出首个用于极端天气预测的大规模多模态数据集MP-Bench,包含逾42万对“原始气象数据-文本描述”样本,覆盖广泛的极端天气场景。基于此,构建了一个可直接接收4D气象输入的气象多模态大模型,并集成了三个即插即用的自适应模块,以提取并融合跨时间、空间及垂直气压层的多维时空动态特征。在MP-Bench上的广泛实验表明,该模型在多项任务中表现卓越,验证了其对强对流天气的深刻理解,为构建自动化、AI驱动的极端天气预报系统迈出了关键一步。
Beyond Myopic Alignment: Lookahead Optimization for Online Class-Incremental Learning
研究介绍:
经验回放,作为在线类增量学习(OCIL)的主流范式,面临一个根本性挑战:当前任务与记忆数据梯度方向往往存在冲突,从而加剧灾难性遗忘。近期多项研究中展现了基于超梯度的元学习方法在缓解决该问题上展现出显著效果,但其内在机制尚缺乏系统性解释。本文首先对这类方法进行了形式化分析,揭示了超梯度的元方法如何隐式地对齐不同梯度方向,并指出这种对齐机制的局限性——仅基于当前参数状态下的一阶梯度信息进行修正。因此,我们引入了前瞻优化(LOR),在每一步更新前主动探索损失景观的近邻结构:沿不同可塑性-稳定性权衡方向执行多个预更新,引导模型收敛至更平坦的几何结构,并从理论上分析了这一框架的鲁棒性。大量实验表明,LOR在多个基准上的准确率和遗忘等指标上相比现有方法均取得领先性能,为OCIL引入了一种更加鲁棒的优化范式。
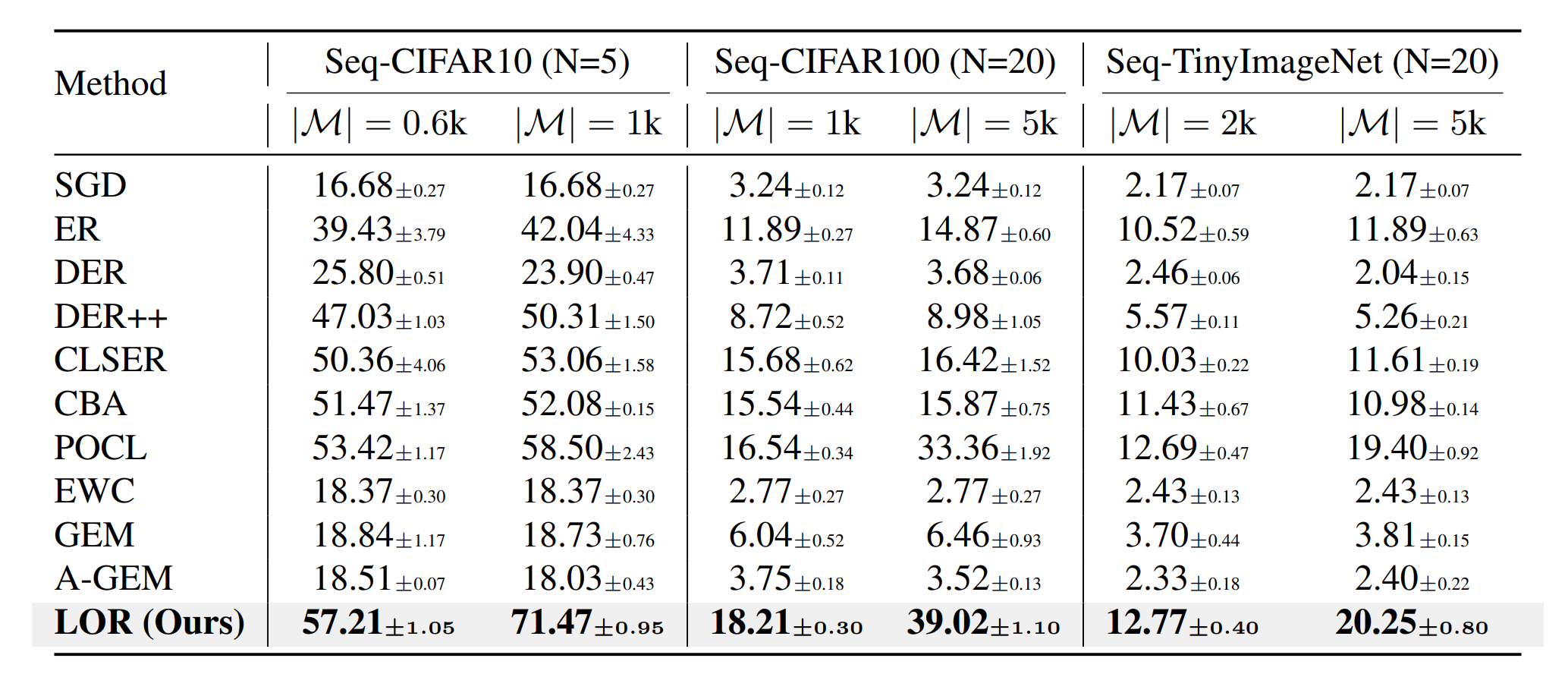
17. STAvatar:面向单目三维头像重建的软绑定与时序密度控制方法
STAvatar: Soft Binding and Temporal Density Control for Monocular 3D Head Avatars Reconstruction
研究介绍:
从单目视频中重建高保真且可驱动的三维头像仍然是一项具有挑战性且至关重要的任务。现有基于 3D 高斯泼溅的方法通常将高斯绑定到网格三角形上,并仅通过线性混合蒙皮(Linear Blend Skinning)建模形变,因而只能建模刚性运动且表达能力受限。此外,这类方法缺乏针对瞬时可见区域(如口腔内部、眼睑等)的专门处理策略。为克服上述局限,我们提出了 STAvatar,其包含两个关键部分:(1) 一种 UV 自适应软绑定框架,融合基于图像与几何的先验信息,在 UV 空间中学习每个高斯的特征偏移。该 UV 表示支持动态重采样,从而与自适应密度控制机制完全兼容,并增强了对形状与纹理变化的适应能力。(2) 一种时序自适应密度控制策略,首先对结构相似的视频帧进行聚类,以实现更具针对性的高斯密度判据计算;其次引入一种新颖的融合感知误差作为高斯克隆的判据,用于同时捕捉几何与纹理差异,从而鼓励高斯点在细节区域进行致密化。在四个基准数据集上的大量实验结果表明,STAvatar在重建性能上达到当前最优水平,尤其在捕捉细粒度细节以及重建瞬时可见的区域方面表现突出。
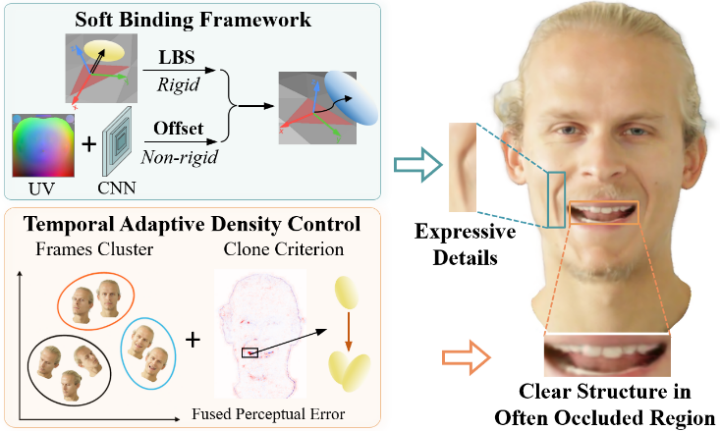
图1. STAvatar 提出了一种软绑定框架和一种时序自适应密度控制策略,用于从单目视频中重建高保真三维头像。
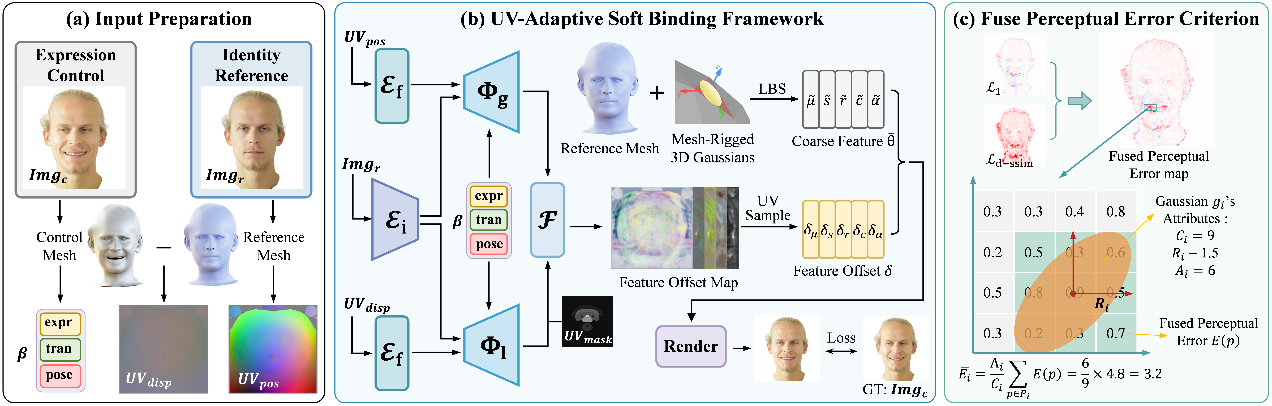
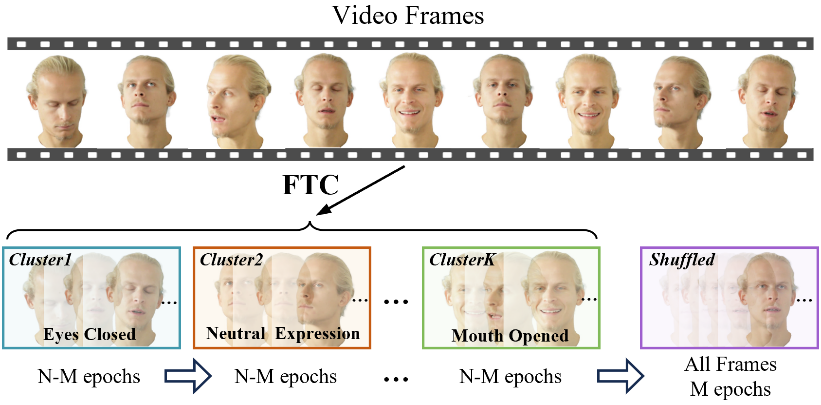
图 3. 基于 FLAME 参数的时序聚类。我们将视频帧划分为 K 个聚类,并在每个聚类的训练过程中分别执行自适应密度控制。
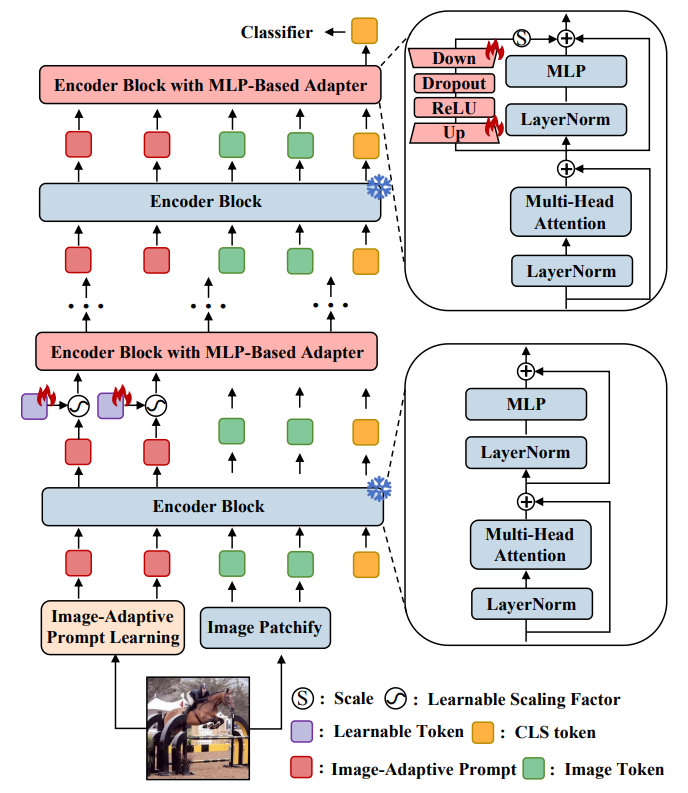
Towards Generalizable AI-Generated Image Detection via Image-Adaptive Prompt Learning
研究介绍:
在人工智能生成图像检测任务中,现有先进方法通常通过部分参数微调来适配预训练基础模型,但对未知生成器的泛化能力仍然有限,因为这类方法往往只能学习训练数据中的有限伪造模式,难以适应新型生成图像不断演变的特征。为此,本文提出图像自适应提示学习方法(IAPL),其核心思想是在测试阶段根据输入图像动态调整提示信息,而不是像传统提示学习那样在训练后固定提示参数,从而提升模型对各类伪造图像的鲁棒性与适应性。具体而言,该方法在CLIP ViT图像编码器中引入了MLP-based adapters、learnable tokens和Image-Adaptive Prompt Learning三个模块,其中Image-Adaptive Prompt Learning是核心创新。它结合Conditional Information Learner提取伪造相关和通用语义信息,并通过Test-Time Token Tuning在推理阶段对提示token进行自适应优化。实验结果表明,该方法在UniversalFakeDetect和GenImage数据集上的平均准确率分别达到95.61%和96.7%。
19.一种基于扩散模型的人脸深度伪造检测与细粒度伪影联合定位框架
DiffusionFF: A Diffusion-based Framework for Joint Face Forgery Detection and Fine-Grained Artifact Localization
论文作者:彭思然、张浩源、高丽、张田硕、朱翔昱、李豹、赵唯松、雷震
研究介绍:
该论文提出了一种名为DiffusionFF的创新框架,旨在同时解决人脸深度伪造检测与细粒度伪影(篡改痕迹)定位的双重挑战。其核心思想是构建一个新颖的“编码器-解码器”架构,其中预训练的伪造检测器被用作强大的“伪影编码器”,而去噪扩散模型则被重新设计为“伪影解码器”。在该架构中,扩散模型以编码器提取的多尺度伪造相关特征为条件引导,逐步生成高保真、细粒度的DSSIM(结构相异度)伪影定位图,从而精准锁定像素级的篡改痕迹。随后,系统通过门控机制将这张细粒度的特征定位图与检测器的高层语义特征进行融合,进而大幅提升了模型的最终真伪检测能力。为了使这两个差异显著的任务都能达到最优效果,作者还引入了一种解耦的两阶段训练策略 。广泛的实验结果表明,DiffusionFF不仅在多个主流数据集上实现了当前最佳(SOTA)的检测性能,在揭示细粒度篡改痕迹方面也超越了现有方法,展现出卓越的有效性、可靠性与模型可解释性。
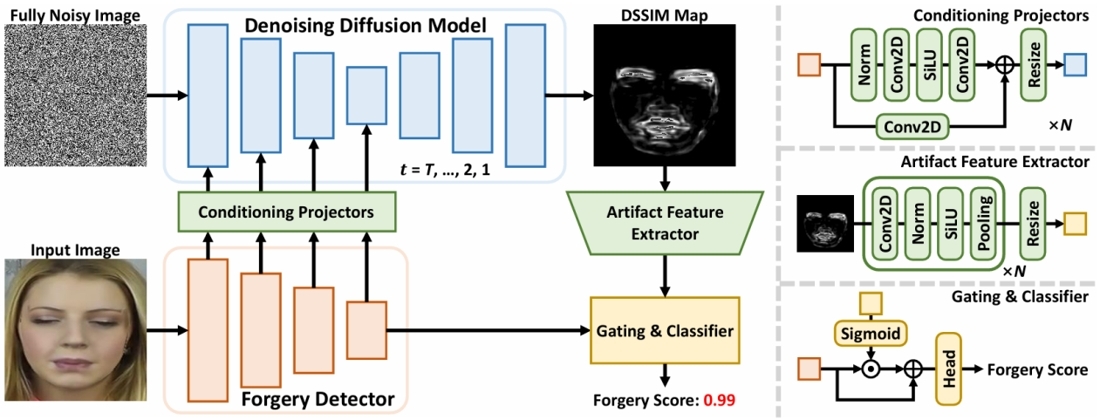
图1. DiffusionFF的整体框架
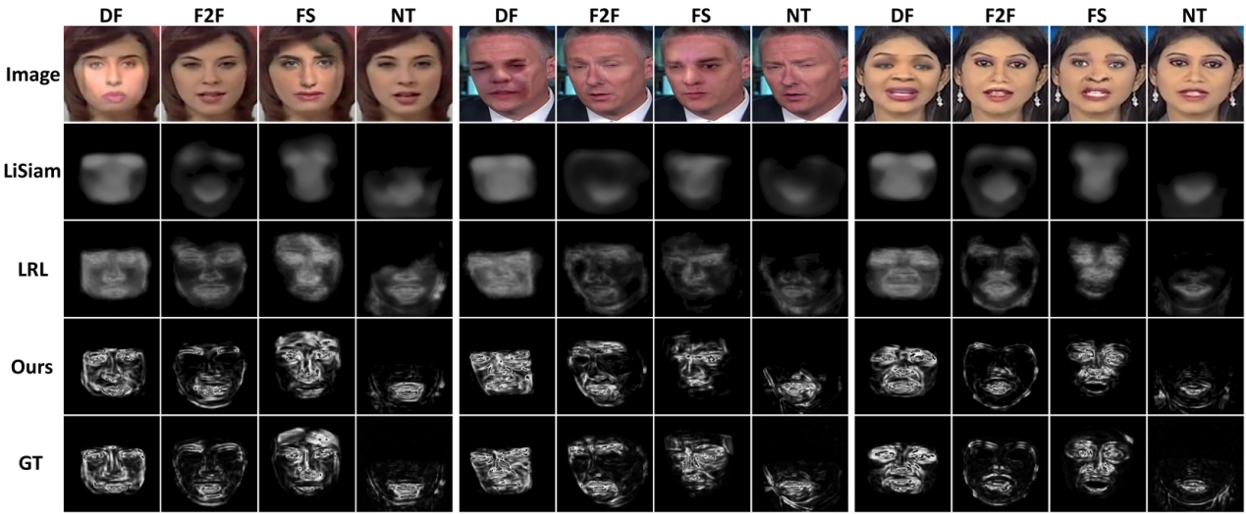
图2. DiffusionFF在FF++数据集上的效果
20. PC-Talk:语音驱动说话人脸生成的精确面部动画控制
PC-Talk: Precise Facial Animation Control for Audio-Driven Talking Face Generation
研究介绍:
近年来,语音驱动的说话人面部生成取得了显著进展,尤其在唇形同步方面。然而,现有方法对说话人面部的控制能力(如说话风格和情感表达)仍然不足,导致生成的面部动作趋于单一。本文针对这一问题,重点提升两项关键因素:唇音对齐控制(LAC) 和 情感控制(EMC),以增强说话视频的多样性与可控性。唇音对齐控制旨在在不同说话风格下实现精确的唇形同步,以模拟多样的说话习惯;情感控制则致力于生成真实、自然的情感表情,并支持情感强度调节及混合情感状态的表达。为实现精确的面部动画控制,我们提出了一种新颖且高效的框架——PC‑Talk,该框架基于隐式关键点形变同时实现唇音对齐控制与情感控制。具体而言,LAC 模块可根据视频参考或预设选项生成具有特定说话风格的唇形同步说话人面部;同时支持唇部运动幅度调节及针对特定发音动作的细粒度风格编辑。EMC 模块则通过纯情感形变生成生动的情感表情,并可精确控制情感强度及不同面部区域的复合情感表现。实验结果表明,我们的方法在控制能力上表现卓越,并在 HDTF 与 MEAD 数据集上取得了当前最优的性能表现。
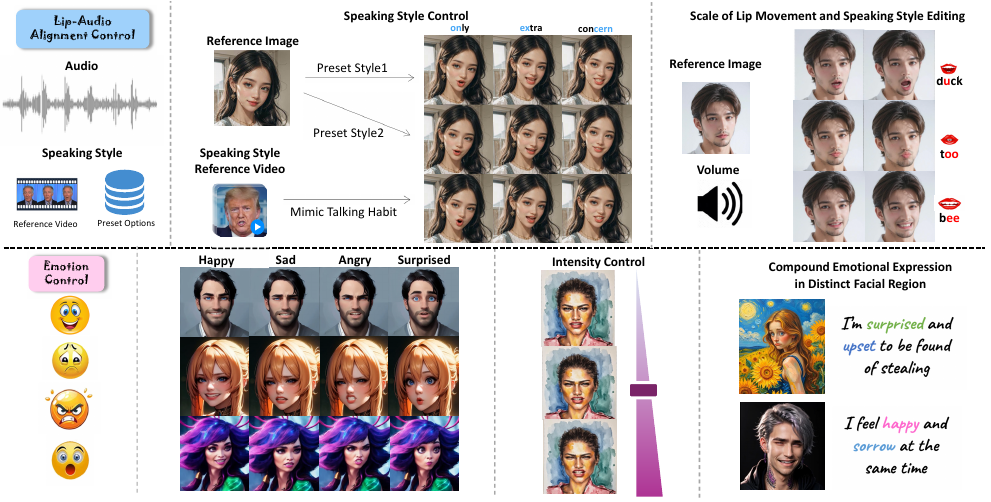
图1. PC-Talk控制效果预览
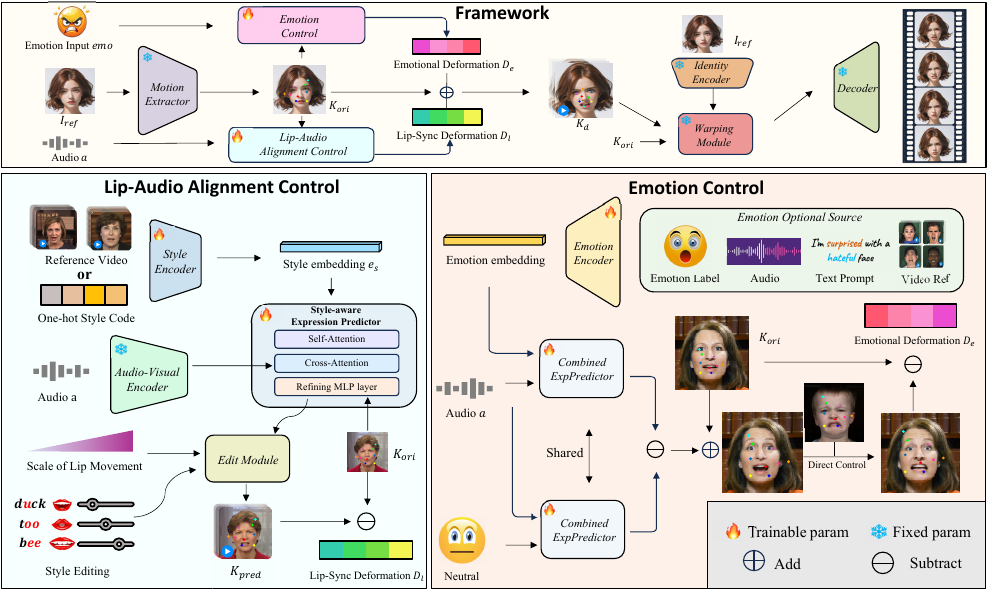
21.从直觉到调查:针对强泛化人脸活体检测的工具增强推理多模态大模型框架
From Intuition to Investigation: A Tool-Augmented Reasoning MLLM Framework for Generalizable Face Anti-Spoofing
论文作者:张浩源, 王珂尧, 张国生, 岳海潇, 谭智文, 彭思然, 张田硕, 谭啸, 陈坤斌, 和为, 王景东, 刘阿健, 朱翔昱, 雷震
研究介绍:
TAR-FAS (Tool-Augmented Reasoning FAS) 框架将人脸防伪 (FAS) 从简单的二分类任务重构为“带视觉工具的思维链” (Chain of Thought with Visual Tools, CoT-VT) 模式 。针对大模型对微观伪造痕迹不敏感的问题,该框架允许模型在初步观察后,主动调用FFT、LBP 等外部视觉工具,对图像的频域、材质、结构等细节进行深度取证。
论文提出了由专家模型引导的数据标注流水线,构建了包含 1.6 万条多轮工具调用推理轨迹的 ToolFAS-16K数据集 。在训练阶段,通过 FAS 知识转移、格式注入及多样性工具组相对策略优化(DT-GRPO),使模型能自主学习高效的工具调用策略 。实验证明,TAR-FAS 在极具挑战性的1对11跨域测试协议下达到了 SOTA性能,相比之前最优方法 HTER 降低了约 3%,显著提升了防伪检测的泛化性与可解释性 。
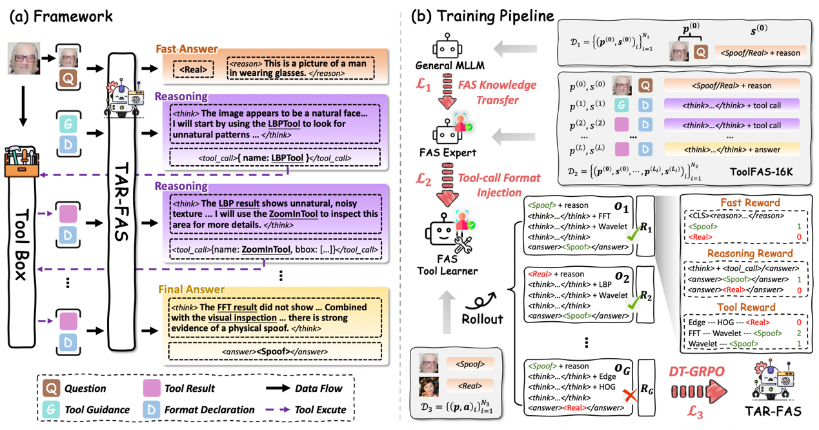
(左侧)TAR-FAS通过借助外部视觉Tool Box实现了多轮推理,将活体检测过程重塑为CoT-VT范式,提升模型泛化性和可信度。
(右侧)通过监督微调和DT-GRPO算法,可以根据任意自定义Tool Box微调预训练模型提升下游任务的泛化性和可信度。
22. AudioStory:使用大型语言模型生成长叙事音频
AudioStory: Generating Long-Form Narrative Audio with Large Language Models
研究介绍:
文本到音频生成(TTA)主要局限于生成短音频片段,但在需要时间连贯性和组合推理的长音频生成方面存在困难。为了填补这一空白,我们提出了AudioStory,这是一个统一生成理解的模型,它将大型语言模型(LLM)与TTA模型(diffuser)集成在一起,以生成结构化的长音频。AudioStory具有很强的指令跟随和推理生成能力。它使用LLM将复杂的叙事指令按照时间顺序分解为多个子事件,从而实现连贯的场景转换和情感基调一致性。AudioStory有两个优异的特性:(1)解耦桥接机制:AudioStory将LLM-diffuser协作分解为两个专门的组件,即用于事件内语义对齐的bridging tokens和用于事件间一致性保持的residual tokens。(2)端到端训练:通过将指令理解和音频生成统一在一个端到端框架内,AudioStory消除了对模块化训练pipeline的需求,同时增强了组件之间的协同作用。此外,我们建立了一个基准测评集,AudioStory-10K,涵盖了动画和自然场景声音等不同领域。大量的实验表明,AudioStory在短音频生成和长音频生成方面都具有优势,在指令跟随能力和音频保真度方面都超过了之前的方法;同时具备较强的音频理解能力。
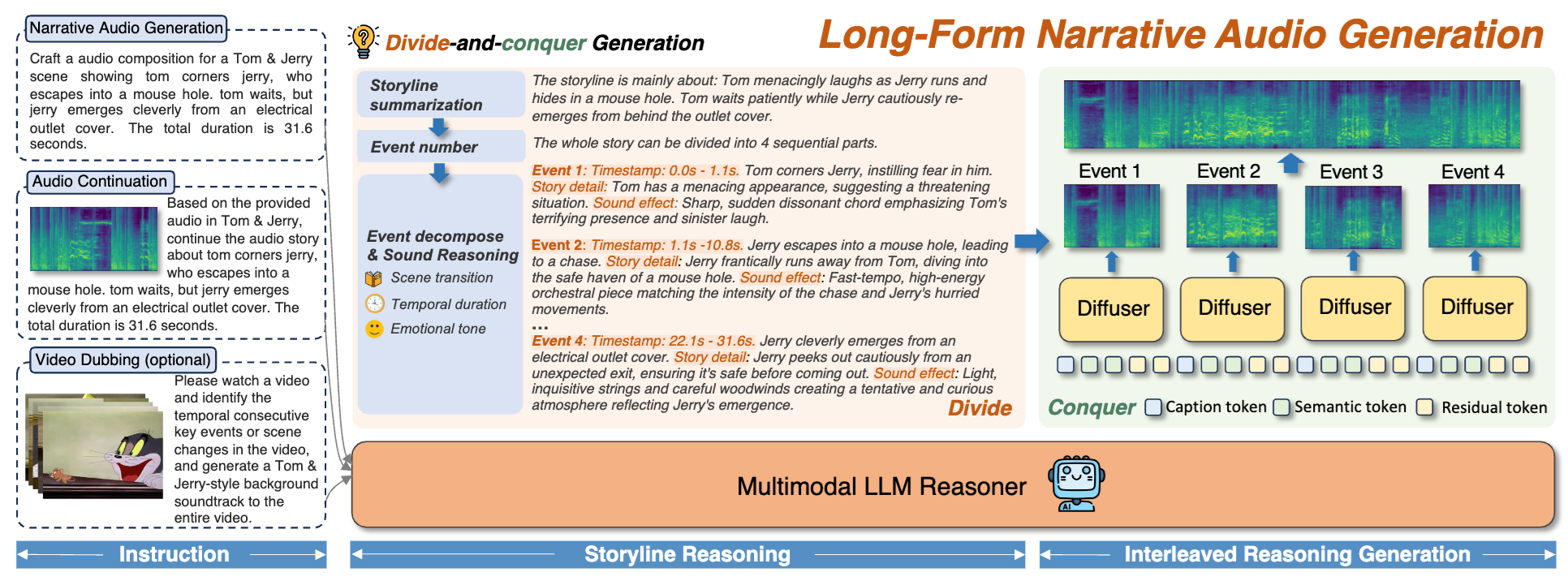
图1. AudioStory能完成多个任务(长音频生成、音频续写、视频配音)
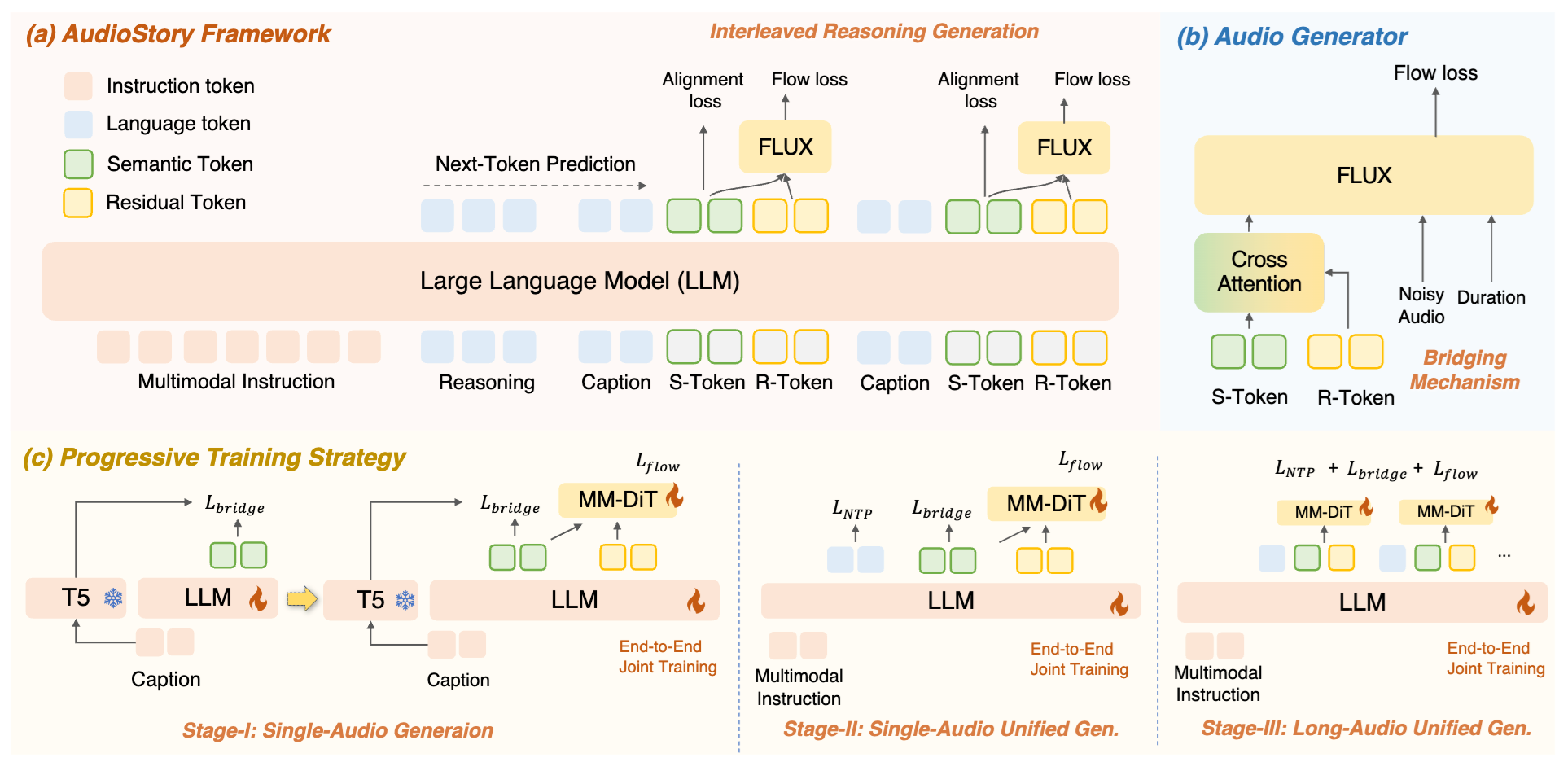
图2. AudioStory的核心模块和训练方法
23. BuildingGPT:结合强化学习的自回归建筑线框重建模型
BuildingGPT: Auto-Regressive Building Wireframe Reconstruction Model with Reinforcement Learning
论文作者:刘昱州,朱灵杰,叶翰樵,刘育俊,黄尚锋,高翔,王瑞胜,申抒含
研究介绍:
本文提出了BuildingGPT,一种结合强化学习的自回归建筑线框重建模型,用于从点云数据中重建建筑物线框结构。不同于传统基于检测或扩散模型的方法,该工作将建筑线框重建任务重构为序列预测问题,通过层级化的建筑线框Token化方式,将结构与语义信息组织为有序的序列表示,从而实现面向下一Token预测的自回归建模。在方法上,首先利用点云编码器将输入点云压缩为固定长度的潜在表示,作为序列生成的起始条件;随后模型在该潜在编码与已生成Token的条件下,自回归地预测后续Token序列;最终通过反Token化过程恢复完整的建筑线框结构。为进一步提升重建结果的结构合理性与语义一致性,模型采用两阶段训练策略:先进行自回归预训练学习基础结构生成能力,再通过直接偏好优化(Direct Preference Optimization, DPO)进行后训练,使生成结果更符合人类偏好与建筑结构规律。该研究从生成范式上突破了传统检测式与扩散式重建框架,为复杂建筑结构的结构化表达与可控生成提供了一种新的建模思路。
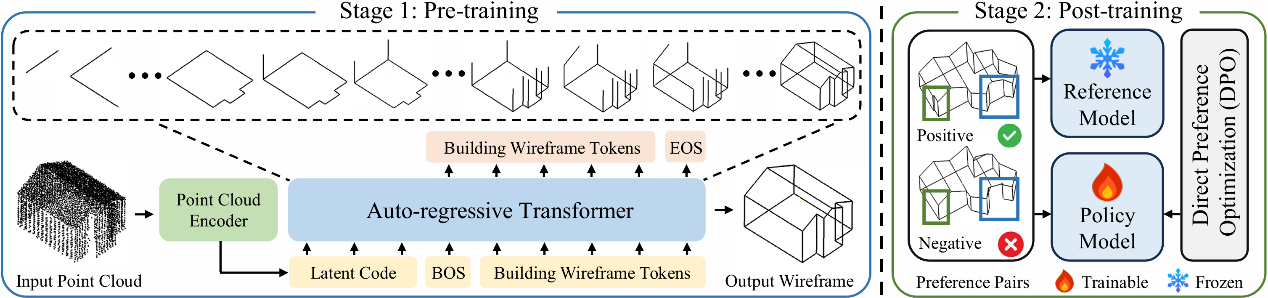
BuildingGPT方法概览。BuildingGPT采用两阶段训练策略,先进行自回归预训练学习基础结构生成能力,再通过直接偏好优化进行后训练提升重建质量。
AG-VAS: Anchor-Guided Zero-Shot Visual Anomaly Segmentation with Large Multimodal Models
论文作者:屈震,陶显,包笑一,王定荣,曲世辰,张正涛,王欣刚
研究介绍:
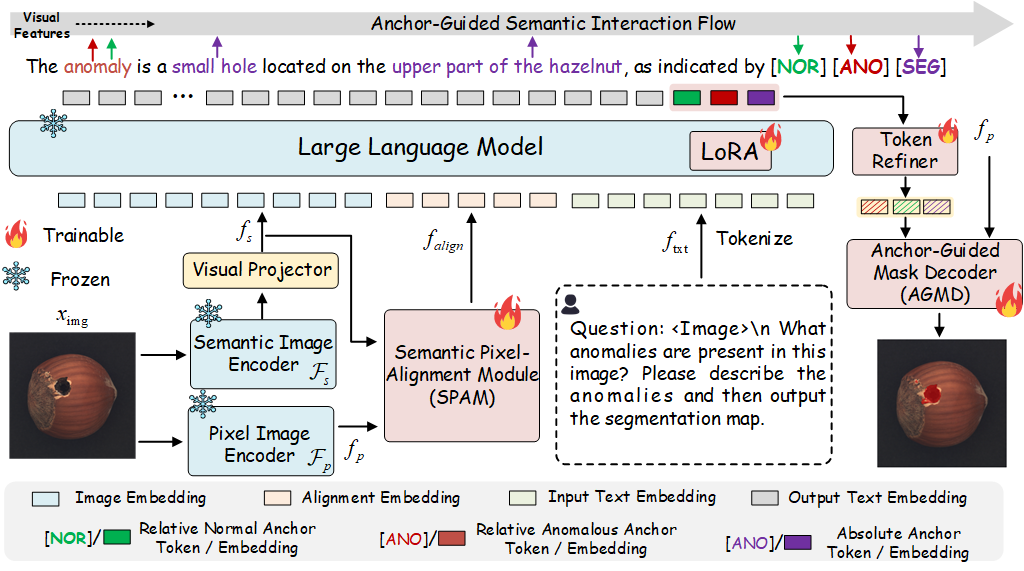
本文针对零样本视觉异常分割中大规模多模态模型在异常语义表达抽象、语义与像素对齐不足等问题,提出了一种锚点引导的视觉异常分割框架 AG-VAS。该方法通过引入三个可学习的语义锚点标记 [SEG]、[NOR] 和 [ANO],构建统一的锚点引导分割范式。其中,[SEG] 作为绝对语义锚点,将抽象的异常概念转化为具备空间指向性的具体视觉实体;[NOR] 与 [ANO] 则作为相对锚点,刻画不同类别中正常与异常模式之间的语境对比关系。为进一步提升跨模态对齐能力,本文设计了语义-像素对齐模块(SPAM),以增强语言级语义嵌入与高分辨率视觉特征之间的映射关系,并提出锚点引导掩码解码器(AGMD),实现基于锚点条件约束的精细异常定位。此外,构建了大规模指令数据集 Anomaly-Instruct20K,将异常知识组织为关于外观、形状及空间属性的结构化描述,以促进语义锚点的有效学习与融合。大量工业与医疗基准实验结果表明,AG-VAS 在零样本设定下取得了稳定且领先的性能表现。
25.PlanaReLoc:面向三维平面基元匹配区域性结构的相机重定位
PlanaReLoc: Camera Relocalization in 3D Planar Primitives via Region-based Structure Matching
研究介绍:
基于结构的视觉重定位方法在建立或回归查询图像与地图之间的关联时,长期以来主要致力于获取点级对应关系(point correspondence)。然而,本项工作首次提出将平面作为结构化场景的地图表示基元,探究其在相机六自由度(6-DoF)位姿估计中的应用价值。平面基元不仅是射影几何中的基本实体,同时也是一种基于区域的表征形式,且承载着丰富的结构信息与语义信息。受这一特性启发,本文设计了PlanaReLoc——一种轻量的“以平面为中心”的重定位范式。在该范式中,特征匹配网络在学习得到的统一嵌入空间中,对查询图像与地图中的平面基元进行跨模态关联;随后,在鲁棒位姿估计框架下求解并优化6-DoF相机位姿。在ScanNet与12Scenes数据集上跨越数百个场景的大规模实验表明,平面基元在跨模态的结构特征关联任务中具备显著优势,这使得该方法无需逐场景训练,在无真实地图纹理/颜色、无位姿先验的情况下,实现了可靠的相机重定位效果。
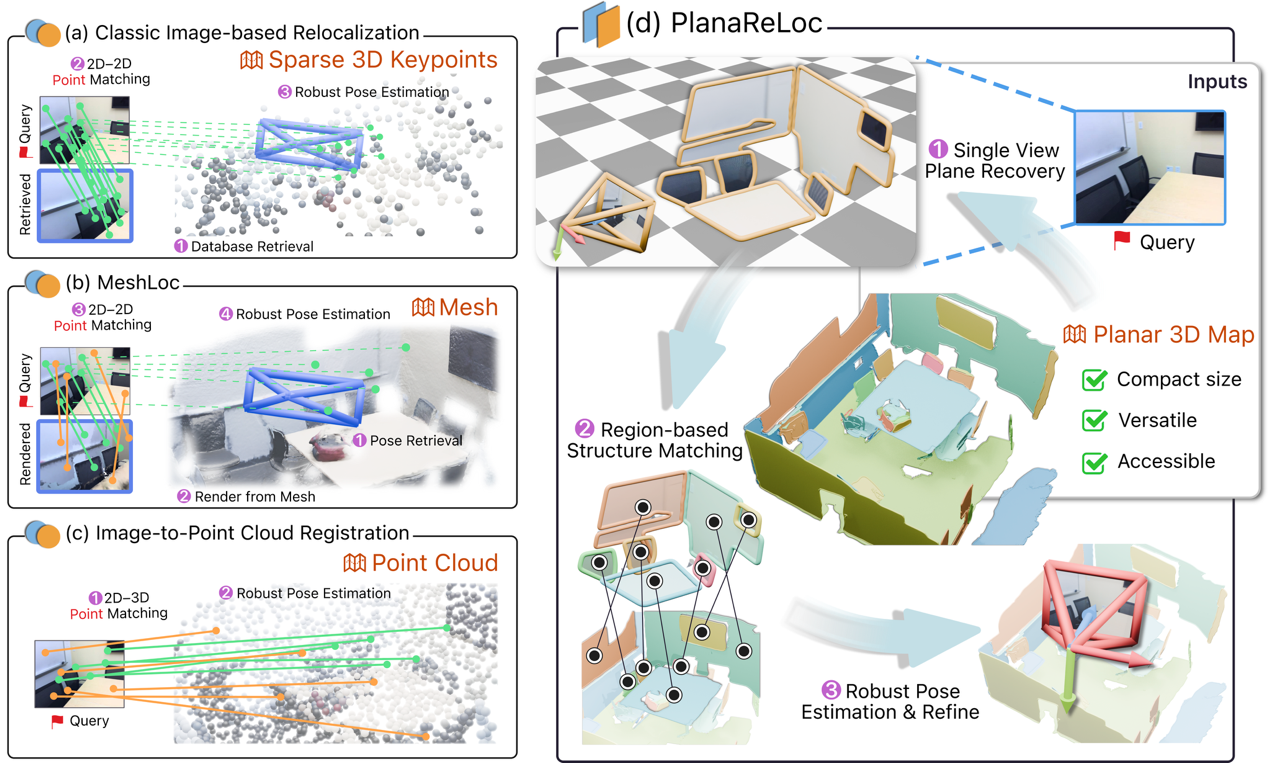
PlanaReLoc方法概览。(a-c) 现有方法依赖点级对应关系;(d) 本文基于紧凑的三维平面地图建立跨模态平面对应关系,实现轻量级6-DoF相机重定位。
26.相同的注意力,不同的真相:将Logit-Lens与视觉注意力结合以检测和缓解 LVLM中的物体幻觉问题
Same Attention, Different Truths: Put Logit-Lens over Visual Attention to Detect and Mitigate LVLM Object Hallucination
研究介绍:
大型视觉-语言模型(LVLMs)常出现物体幻觉,即生成图像中不存在的物体。以往研究多将其归因于视觉注意力不足。然而,我们发现,在模型的中后期层中,真实物体与幻觉物体可以获得同样强的视觉注意力。这表明,问题关键不在于“关注多少”,而在于关注了什么以及为何关注。为此,我们利用 Logit Lens 解码高注意力区域的视觉特征,发现真实物体对应的区域可被正确解码为目标 token,而幻觉物体对应区域则不能。进一步地,我们识别出了两种幻觉机制:(i)视觉不确定性:由语义相似或易混淆区域引发,遮蔽这些区域即可缓解幻觉;(ii)语境先验:由强共现先验触发,即使遮蔽最初关注区域,幻觉仍会持续并转移注意力。基于上述发现,我们提出了一个无需训练的检测–缓解框架,包括用于幻觉检测的Logit-Lens一致性检验,以及针对不同机制的缓解策略:高注意力区域遮蔽和视觉证据增强解码。该方法在多个幻觉基准上取得了最先进的效果。
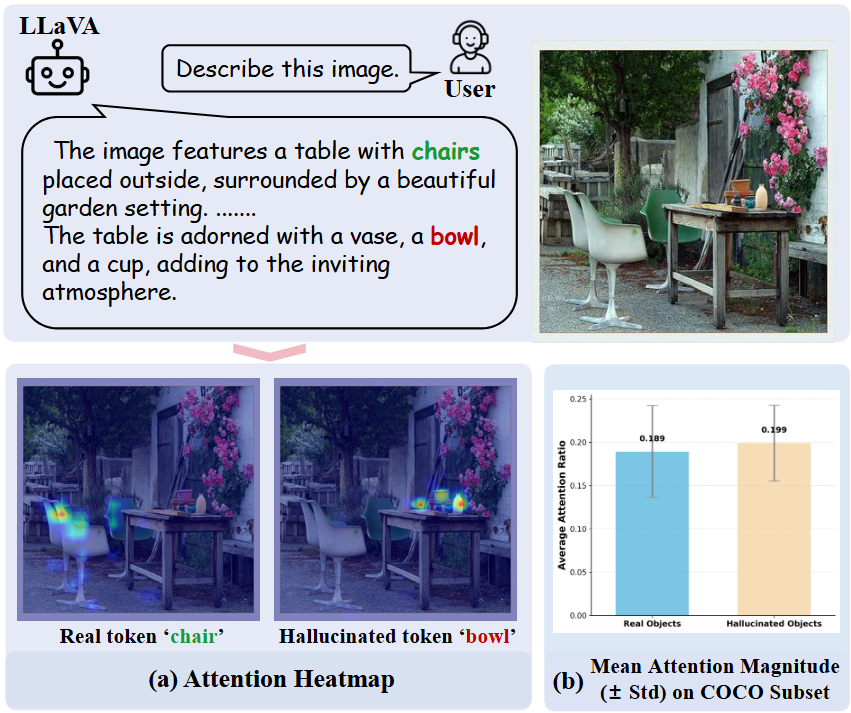
图1. 不同于以往将物体幻觉归因于视觉注意力不足的研究,我们发现真实物体与幻觉物体往往具有相同的注意力强度。如图 (a) 的定性结果和图 (b) 的定量结果所示,这体现了“相同的注意力,不同的真相(Same Attention, Different Truths)”。
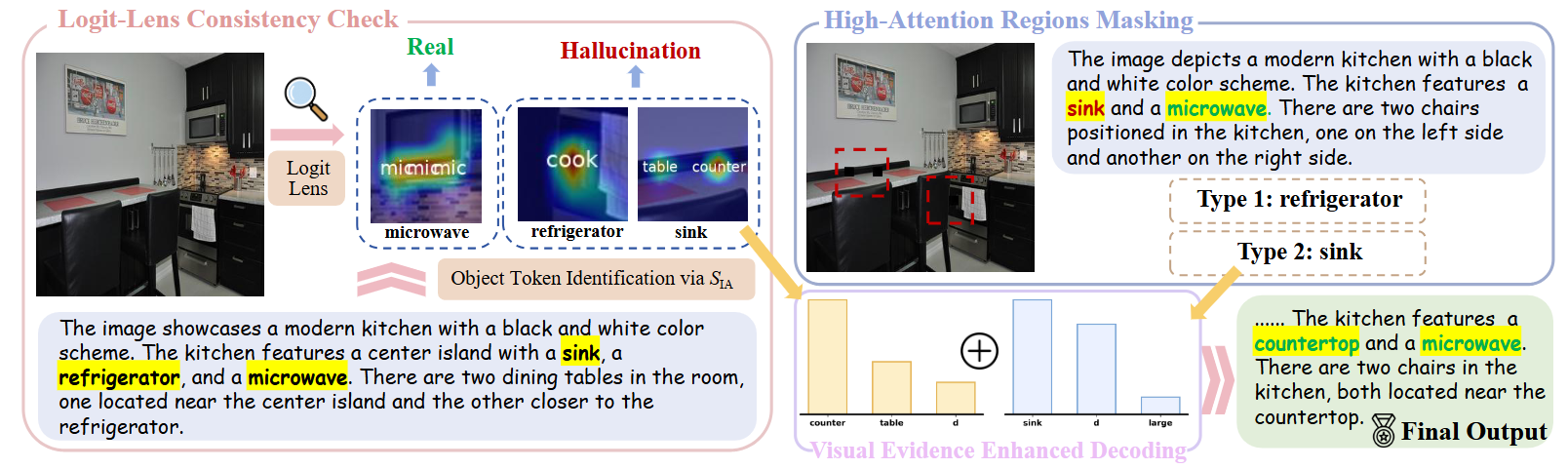
图2. 我们提出的 Detect–Mitigate 框架整体结构。该框架包含三个组成部分。首先,Logit-Lens 一致性检验(LLCC)用于检测响应中的幻觉目标 token。随后,高注意力区域遮蔽(HARM)在生成中间输出的同时,将其划分为两种不同类型的幻觉。若检测到第二类幻觉,则进一步通过视觉证据增强解码(VEED)进行处理,以生成最终结果。
27. NeoVerse: 用开放场景单目视频增强四维世界模型
NeoVerse: Enhancing 4D World Model with in-the-wild Monocular Videos
研究介绍:
NeoVerse是一个面向通用场景的4D世界模型。当前4D世界模型建模方法在可扩展训练上存在局限性,这主要归结于昂贵的多视角数据或是过于繁琐的离线预处理流程。NeoVerse旨在突破这一瓶颈,其核心理念是将整个训练管线扩展至海量开放场景单目视频。通过引入无需位姿的前馈4D高斯重建与创新的在线单目退化模拟机制,NeoVerse在百万级单目视频上进行训练,具备强大的泛化能力。它打破了对特定数据的依赖,仅需输入单目视频即可在30秒内(单卡A800下)高效实现4D场景构建与新轨迹视频生成。目前,该模型在各项重建与生成指标上均处于先进水平,并且在影视创作、具身智能、自动驾驶等领域展现了广泛的应用潜力,支持4D重建、精准相机漫游、多视角生成、视频编辑、视频稳像、三维点跟踪及反事实长尾数据生成等丰富任务。
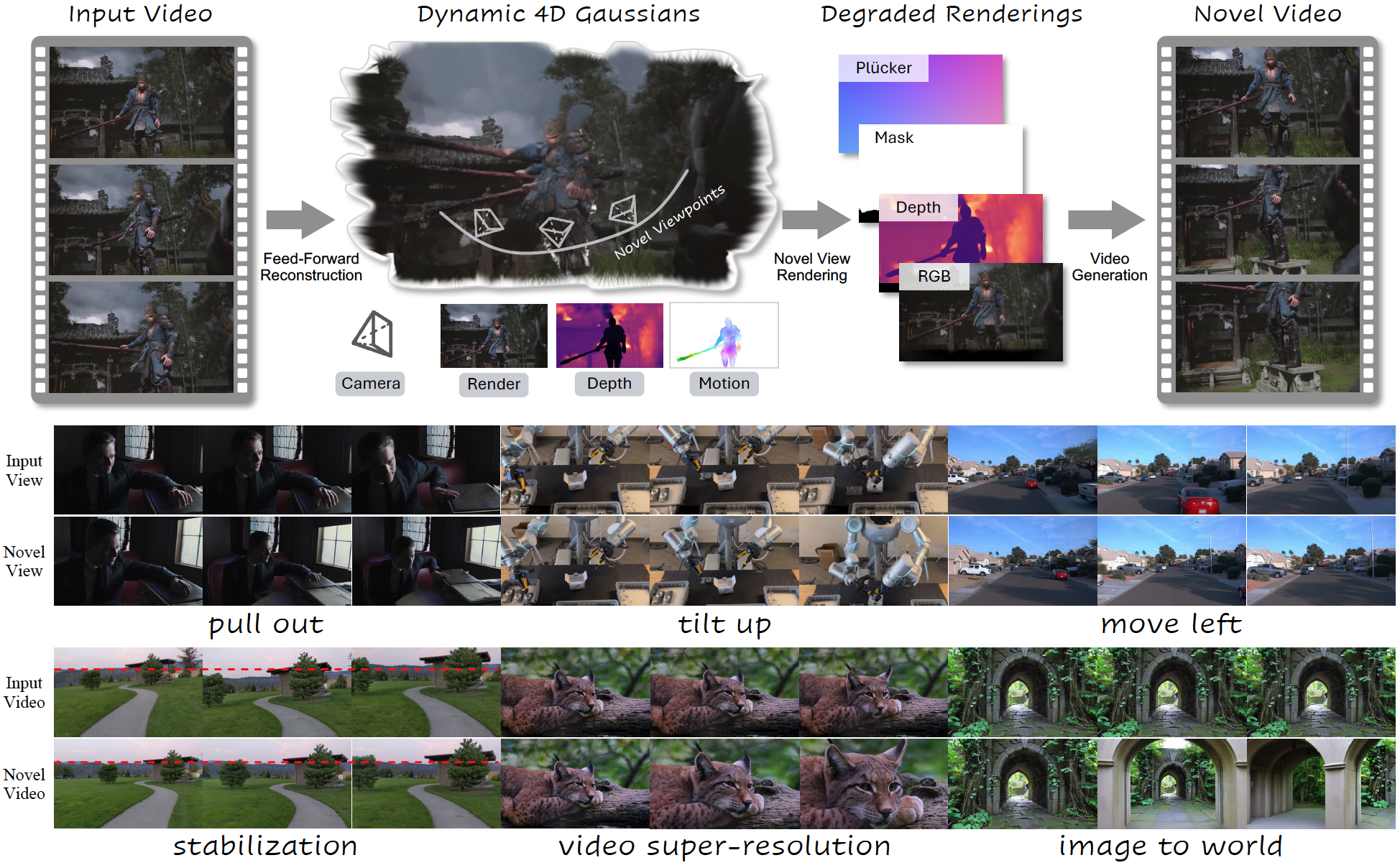
图1. NeoVerse示意图。NeoVerse通过前馈方式从单目视频重建4D高斯。这些4D高斯可以从新视角渲染出退化画面、深度等信息,并将以退化信息作为条件生成高质量的新视角视频。
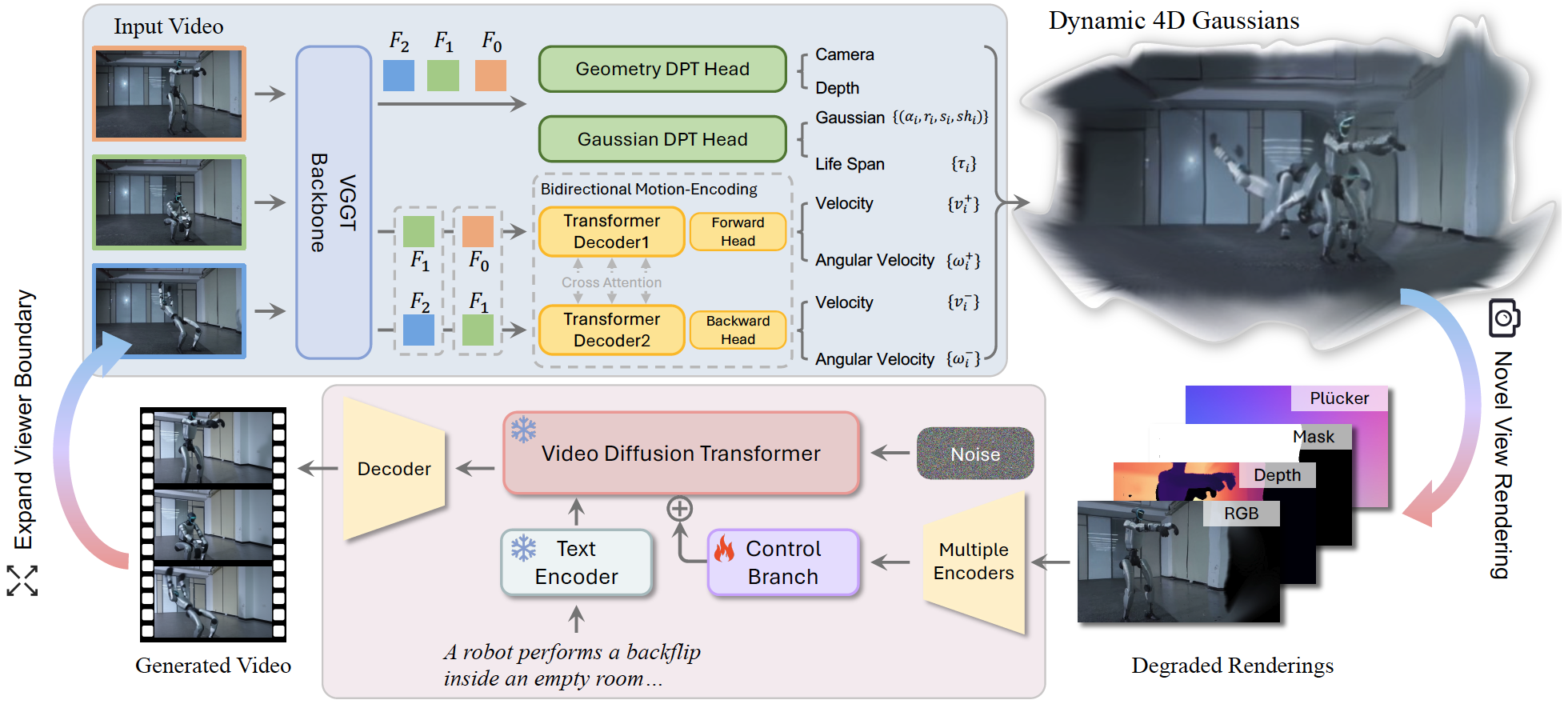
图2. NeoVerse框架。在重建部分,我们提出了无需姿态输入的前馈4DGS重建模型并支持双向运动建模。4DGS在新视角下的退化渲染作为条件输入给视频生成模型。在训练过程中,我们通过单目退化模拟构建退化条件,并将原始视频本身作为训练目标。
28. SimScale:基于大规模真实世界仿真的自动驾驶学习方法
SimScale: Learning to Drive via Real-World Simulation at Scale
论文作者:田浩辰,李天羽,刘浩晨,杨佳智,邱一航,李广,王君礼,高胤峰,张彰,王亮,叶航军,陈龙,李弘扬
研究介绍:
实现完全自动驾驶系统需要在广泛场景中学习合理决策能力,包括安全关键与分布外情形。然而,此类场景在由人类专家采集的真实数据中占比较低。为弥补数据多样性不足,我们提出一种新颖且可扩展的仿真框架SimScale,可基于已有驾驶日志合成大规模未见状态。该框架结合先进神经渲染与可交互环境,在扰动自车轨迹控制下生成高保真多视角观测;同时为新合成状态构建伪专家轨迹生成机制,以提供动作监督。基于合成数据,我们发现对真实与仿真样本进行简单协同训练,即可在多个规划方法与具有挑战性的真实基准上显著提升鲁棒性与泛化能力,在 navhard 上最高提升 6.9 EPDMS,在 navtest 上提升 2.9。更重要的是,即使不引入额外真实数据,仅通过扩展仿真数据规模,策略性能亦可平滑提升。我们进一步系统分析了该虚实混合学习框架的关键机制,包括伪专家设计与不同策略架构下的扩展特性。
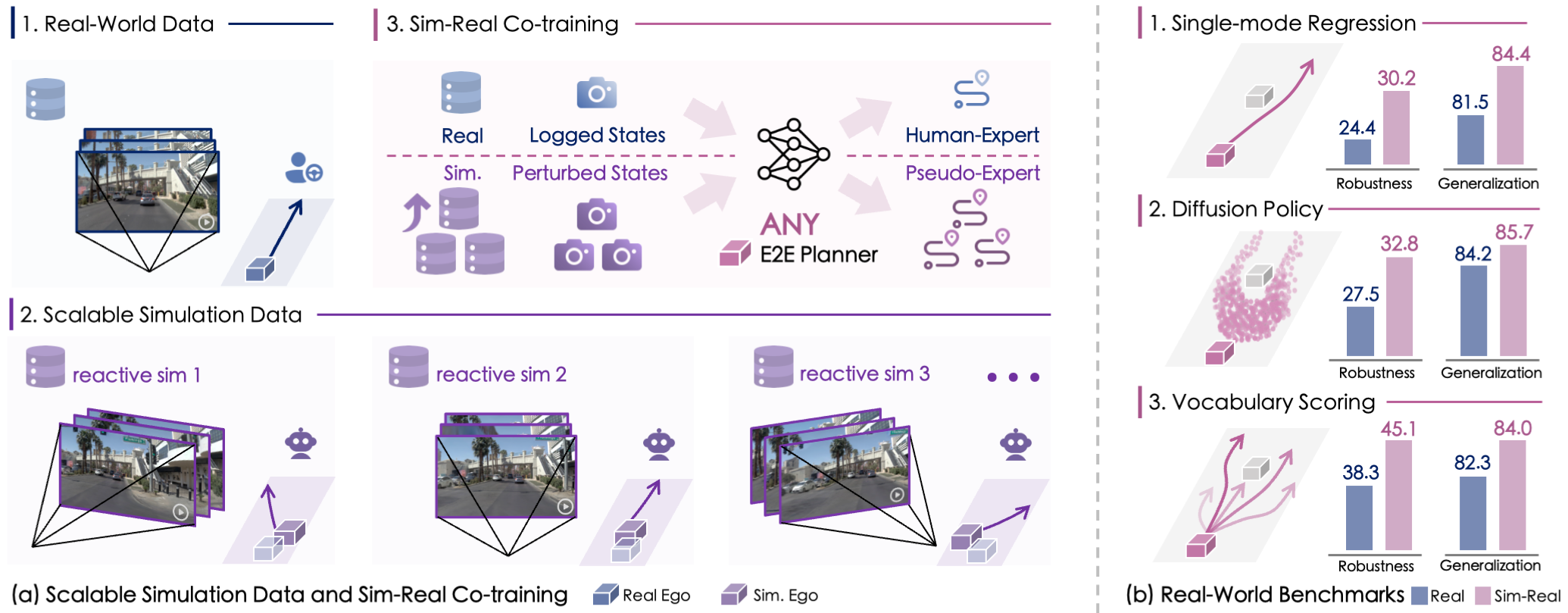
图1. SimScale示意图。SimScale高效的虚实混合训练范式,通过规模化地增加仿真数据,实现任意端到端规划器的鲁棒性和泛化性协同提升。
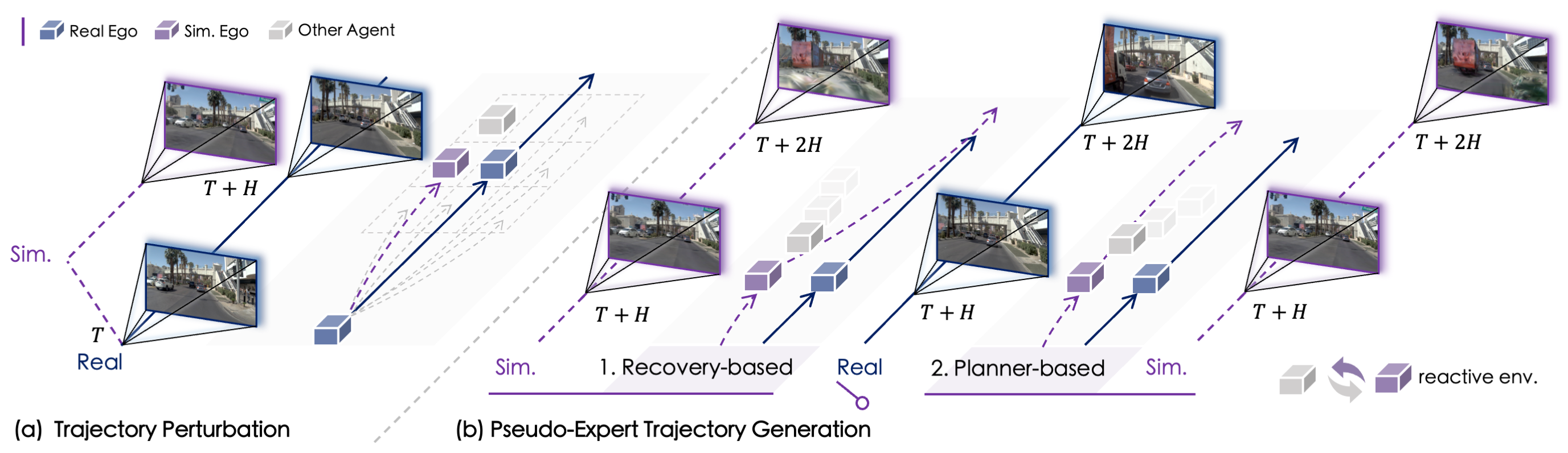
图2. SimScale仿真框架。SimScale可扩展的仿真数据生成框架,基于先进神经渲染引擎与可交互环境,规模化生成高保真仿真图像以及伪专家示范。
Think-Then-Generate: Structural Chain-of-Thought Reasoning for Consistent 3D Generation
研究介绍:
近年来,利用预训练扩散模型的视觉先验生成3D资产已取得显著进展。然而,由于2D扩散模型缺乏固有的3D几何先验,生成结果常存在空间幻觉与多视图不一致问题。为此,本文提出Thoughtful3D框架,通过引入结构化思维链(CoT)推理提升3D内容生成质量,以缓解不一致性问题并抑制幻觉。具体而言,我们设计了一种双阶段结构化CoT策略:(1)3DBlueprint-CoT在初始化阶段通过文本语义解析与逻辑演绎显式规划3D生成过程;(2)3DRefine-CoT通过分析多视角渲染结果动态评估潜在不一致性,采用多轮迭代精修机制抑制幻觉并增强跨视图一致性。为进一步提升视图间一致性,我们提出跨视图语义外观对齐策略,通过建立不同视角下相同特征的动态几何关联来增强多视图一致性。大量实验表明,Thoughtful3D显著提升了生成3D资产的质量与一致性。
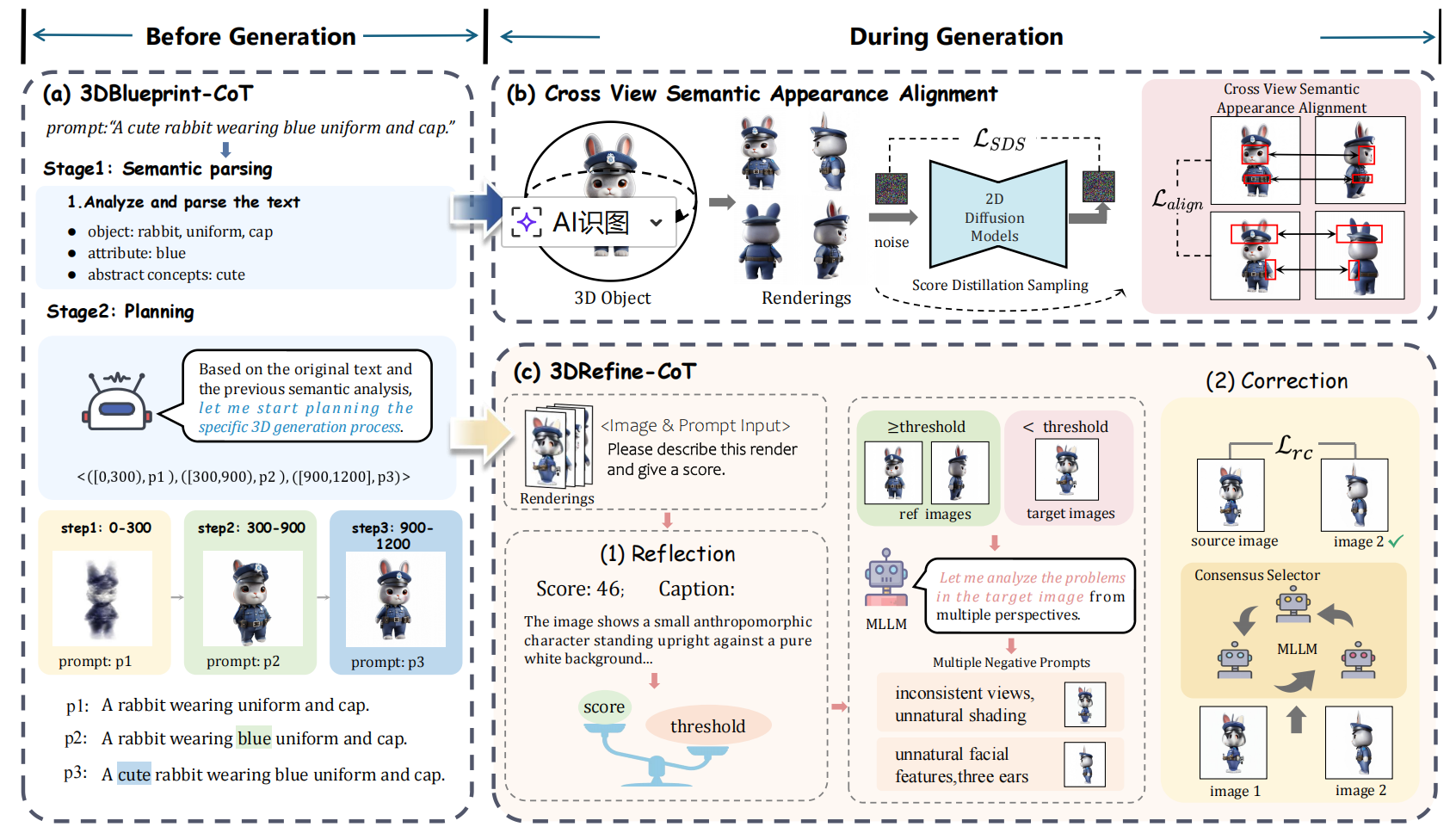
图1. Thoughtful3D的整体框架。 生成前,3DBlueprint-CoT基于输入语义规划整个生成流程。生成过程中,我们通过两种策略联合优化模型:(1)3DRefine-CoT通过结构化推理检测不一致性(反思阶段),并通过多数投票选择最优修正渲染结果(修正阶段);(2)跨视图对齐基于共享语义将多视图潜在特征拉近,实现动态对齐,以获得跨视图一致性。
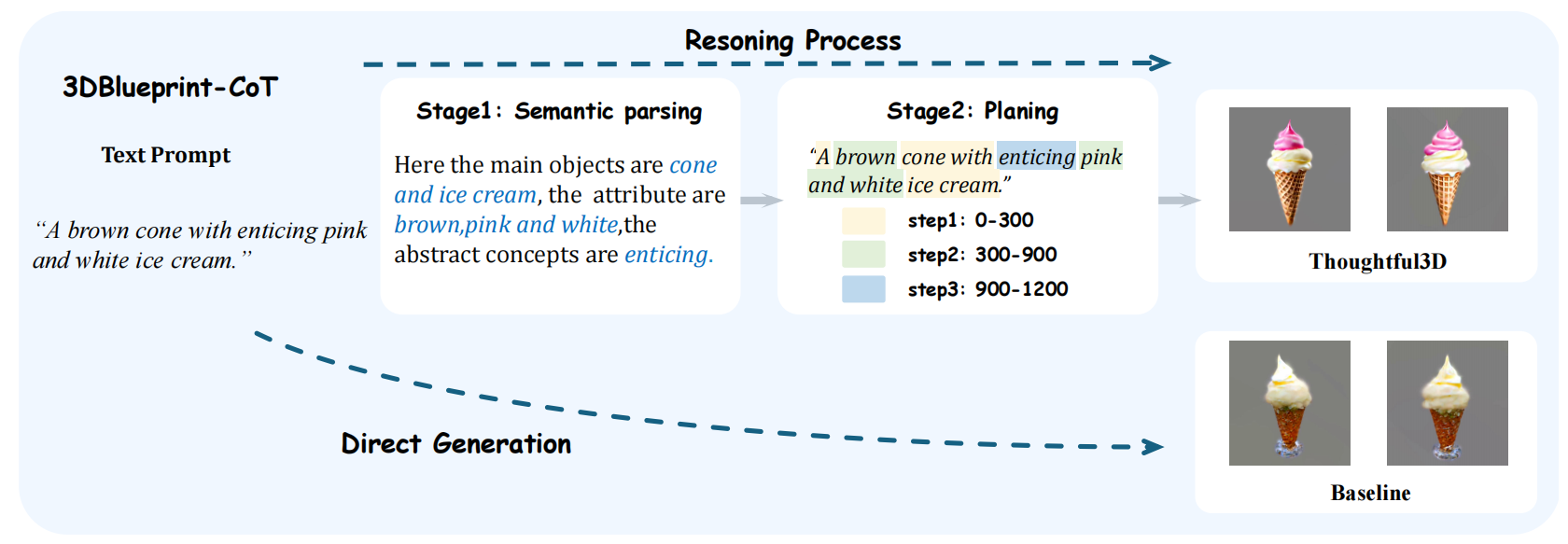
图2. 3DBlueprint-CoT的推理过程。 第一阶段对输入提示进行语义解析与分析;基于此理解,第二阶段规划整体生成过程。
Towards Fine-Grained Attribution: Instance-Aware Preference Optimization for Aligning Diffusion Models
研究介绍:
直接偏好优化已实现将扩散模型与人类反馈相对齐。然而,现有方法严重依赖于图像级偏好,这在图像固有的空间维度上存在稀疏奖励的问题:尽管某张图像可能在整体上更受偏好,但其局部可能包含较差的实例。对这些区域应用相同的正向偏好,会不公平地奖励干扰性区域,同时惩罚信息性区域,从而导致性能次优和学习效率低下。为解决此问题,本文提出了 IAPO,一种实例感知的偏好优化方法,通过引入实例级信用分配机制,将对齐从图像级提升至实例级。本文首先利用视觉语言模型和目标检测模型,自动识别图像对中的对应实例并重新标注,构建了一个高质量的实例级偏好数据集。基于这一细粒度数据集,本文设计了一种新颖的实例对齐损失函数,用于调节标注边界框内的实例级损失,从而抑制干扰因素,实现细粒度的人类偏好对齐。大量实验证明,本文方法不仅在多项基准测试中取得了最先进的性能,而且由于采用了细粒度的实例级偏好标签,实现了更高的训练效率。
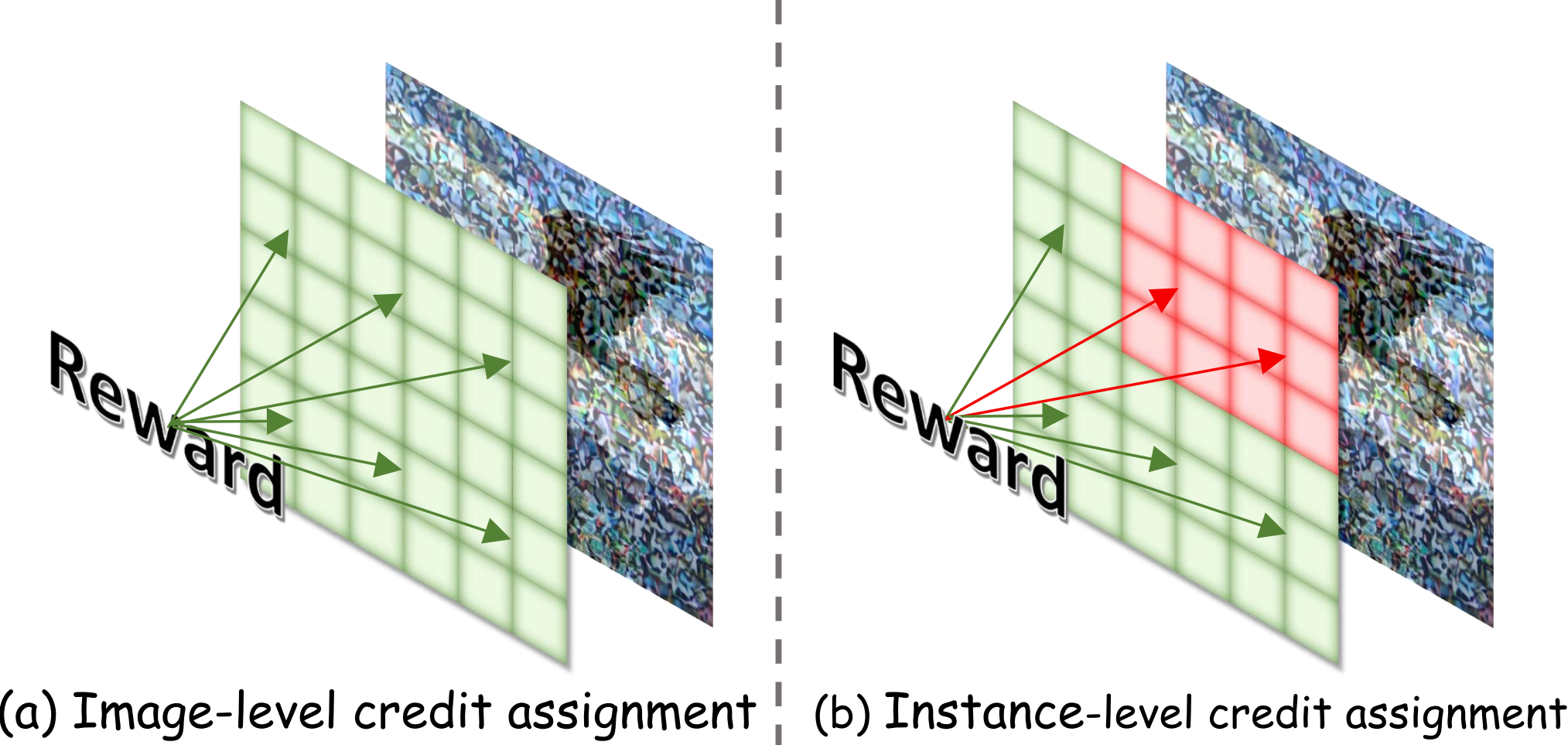
图1. 实例级信用分配。 现有方法将奖励信号均匀传播至所有像素,而本文能够对学习信号进行实例级调制,从而实现细粒度信用分配。
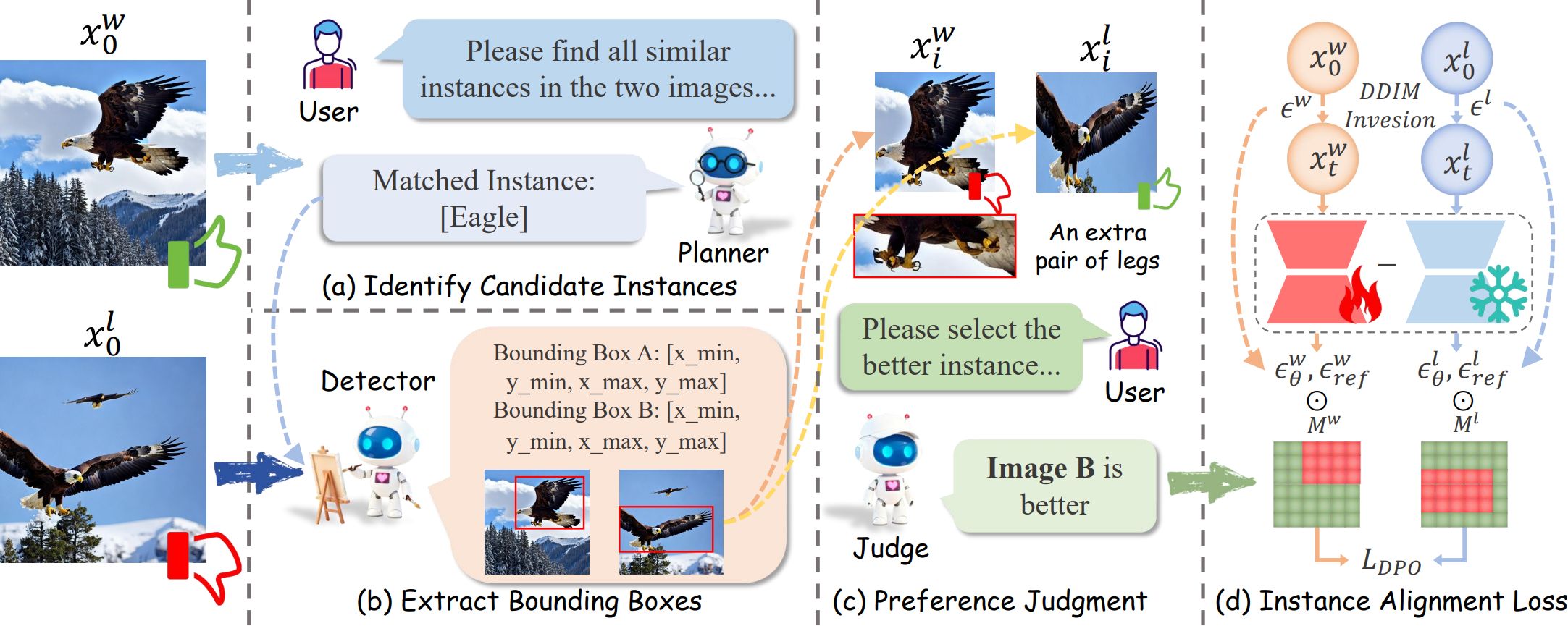
图2. IAPO概述。 本文首先基于Pick-a-Pic v2数据集,利用视觉语言模型检测图像对中的对应实例并重新分配其偏好标签,构建了一个高质量的实例级偏好数据集。基于该数据集,本文设计了实例对齐损失函数,用于增强关键实例的学习信号,同时抑制干扰性实例的影响。
31. Think 360°:评估多模态大语言模型以宽度为中心的推理能力
Think 360°: Evaluating the Width-centric Reasoning Capability of MLLMs Beyond Depth
本研究我们提出了一个全面的多模态基准测试,用于评估多模态大模型的推理能力,并明确将重点放在“推理宽度”上,这是对目前研究较多的“推理深度”的一个重要补充维度。具体而言,“推理深度”衡量的是模型进行长链式、序贯推理的能力,其中每一步都紧密且严格地与下一步相连。而“推理宽度”则更侧重于模型进行广泛的试错搜索或多重约束优化的能力:它必须系统地遍历许多可能的并行推理路径,应用各种约束条件来修剪不具前景的分支,并识别有效的解决方案路线以进行高效的迭代或回溯。
为了实现这一目标,我们精心策划了涵盖异构领域的1200 多个高质量多模态测试用例,并提出了一种细粒度的“思维树”评估协议,从而共同量化推理的宽度和深度。我们在不同的难度层级、问题类型和所需技能方面,对12个主要的模型家族(超过30个先进的多模态大模型)进行了评估。结果表明,尽管当前模型在一般或常识性的视觉问答任务上表现出色,但它们仍然难以将深度的顺序思维链与广度的探索性搜索有效结合,以进行真正基于洞察力的推理。最后,我们分析了典型的失败模式,为构建不仅“推理更深”而且“推理更广”的多模态大模型提供了可能的方向。
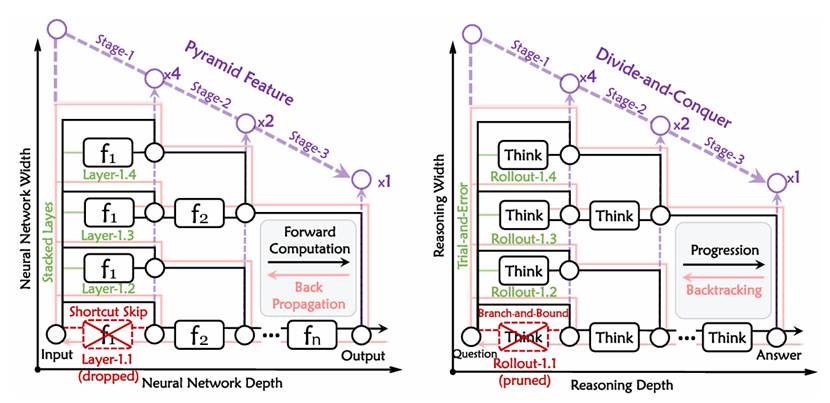
图1. 神经网络信息传播与推理过程中“宽度”和“深度”的概念示意图。借鉴神经网络的经典设计:跳跃连接、金字塔特征、层堆叠以及梯度反向传播,我们将它们类比为剪枝、分治、试错和回溯等策略,以此来区分推理过程中的深度与宽度。

图2. 推理深度与宽度扩展的演示图解。推理深度定义为父子节点长链的长度。它代表得出结论所需的逻辑步骤数量,随逻辑依赖性而扩展(例如,时钟读取任务中,从简单读数到多步计算会延长链条长度)。推理宽度定义为任何层级上兄弟节点的最大数量。它代表所考虑的备选假设或并行分支的数量(例如,迷宫任务中,从5×5 扩展到10×10 会拓宽探索宽度)。
32.扩展与剪枝:最大化轨迹多样性以实现生成模型的高效 GRPO
Expand and Prune: Maximizing Trajectory Diversity for Effective GRPO in Generative Models
研究介绍:
组相对策略优化(GRPO)是实现生成模型对齐的强大技术,但庞大的采样组需求与高昂计算成本之间的矛盾,成为了制约其效能的瓶颈。本文通过实证研究深入探讨了这一权衡问题,并得出两个关键发现。首先,我们发现了“奖励聚集”现象,即大量轨迹的奖励值向样本组均值坍缩,导致其能提供的优化价值极为有限。其次,我们设计了一种名为最优方差过滤(OVF)的启发式策略,并验证了由该策略筛选出的高方差轨迹子集,在优化效果上能够超越未经过滤的庞大样本组。
然而,这种静态的后置过滤方法仍会产生巨大的计算开销,因为它为最终注定被丢弃的轨迹执行了不必要的完整采样过程。为解决这一问题,我们提出了主动式 GRPO(Pro-GRPO),这是一个将基于潜在特征的轨迹剪枝机制动态融入采样过程的全新框架。通过尽早终止陷入奖励聚集的轨迹,Pro-GRPO 显著降低了计算开销。凭借这一高效机制,Pro-GRPO 进一步采用了“扩展与剪枝”策略:首先扩大初始采样组的规模以最大化轨迹探索的多样性,随后在潜在空间中执行多步最优方差过滤,从而成功规避了高昂的计算成本。在基于扩散和基于流的生成模型上开展的大量实验,充分证明了 Pro-GRPO 框架的通用性与有效性能。
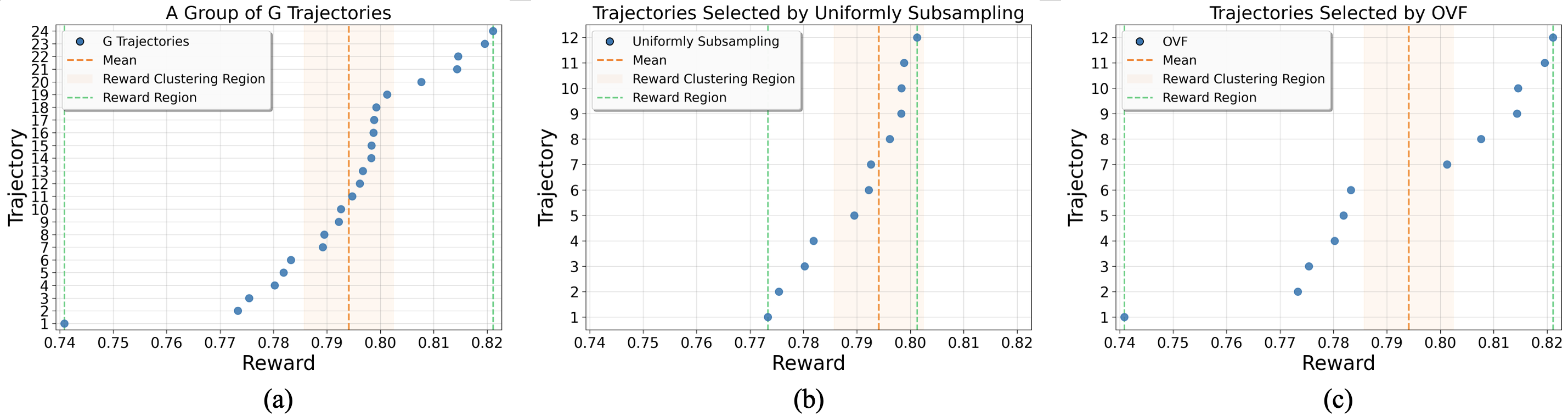
图1. 奖励聚集现象与 OVF 策略效果对比 。(a) 完整的采样组(G=24)呈现出显著的奖励聚集现象 。(b) 传统的均匀子采样(k=12)无法打破这一聚集状态 。(c) 本文提出的 OVF 策略(k=12)通过精准筛选分布两端的极端奖励样本,有效缓解了奖励聚集问题 。
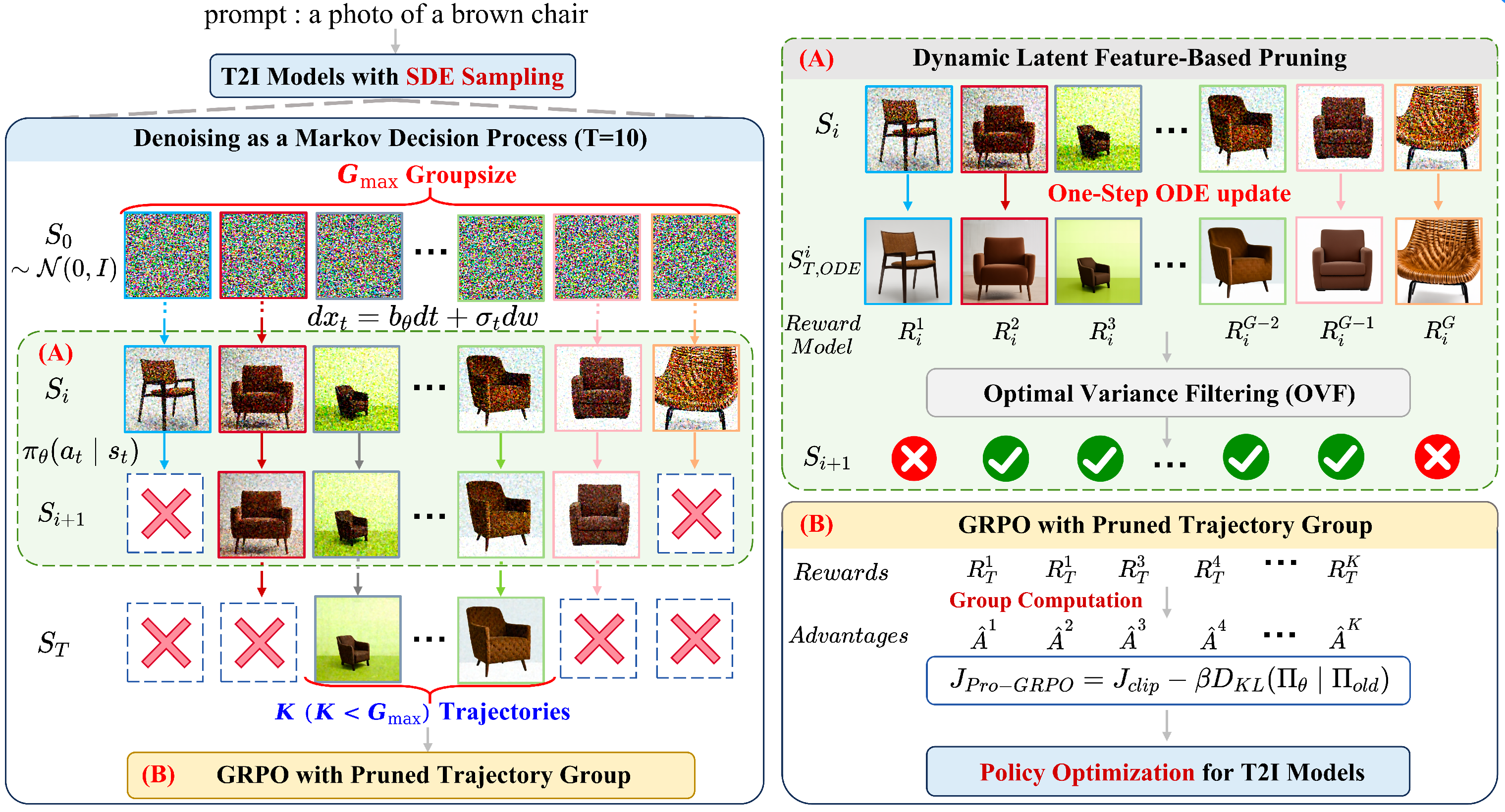
图2. Pro-GRPO 框架总览。在 T 步去噪过程中,Pro-GRPO 采用动态的“扩展与剪枝”策略 。初始阶段,框架将采样组扩展至 Gmax 以最大化探索空间 。在中间检查点 Si,(A) 动态潜在特征剪枝通过单步 ODE 更新预测终端奖励,随后 OVF 策略精准保留高方差子集,并提前终止其余轨迹(红叉所示),将轨迹组逐步缩减至 K 个幸存样本 。(B)最后,针对剪枝后的组执行 GRPO,计算这 K 个样本的归一化优势并更新策略,从而以极低的计算成本实现卓越的对齐性能 。
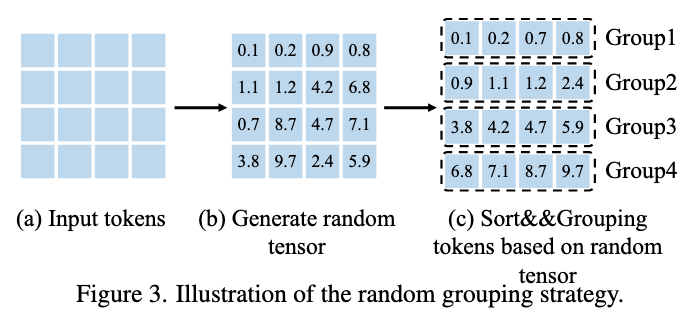
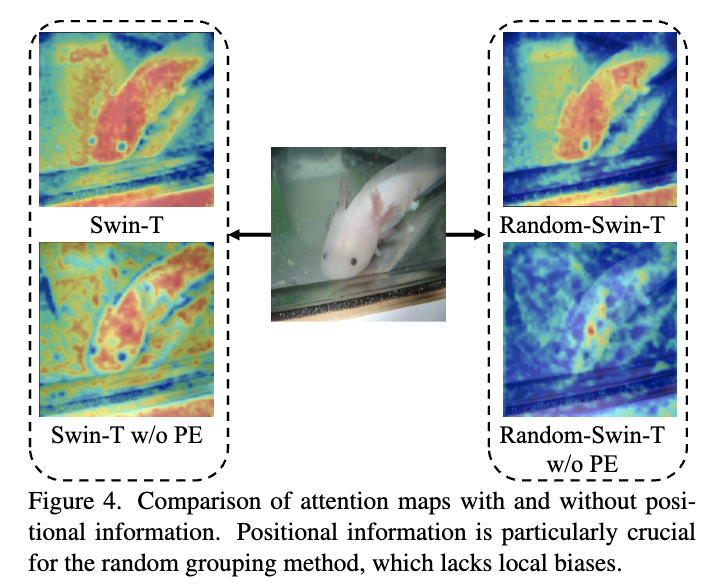
Random Wins All: Rethinking Grouping Strategies for Vision Token
研究介绍:
自 Transformer 被引入视觉架构以来,其二次方复杂度一直是一个显著问题,许多研究工作都致力于解决这一问题。一种代表性的方法涉及对 token 进行分组,在每个组内执行自注意力计算,或将每个组内的 token 池化为单个 token。为此,人们提出了各种精心设计的分组策略,以提升性能。在此,我们提出以下问题:这些精心设计的分组方法真的必要吗?因此,我们提出了随机策略,这是一种针对视觉 token 的简单且快速的随机方法。我们在多个基线模型上验证了该方法,实验表明,随机分组几乎优于所有其他分组方法。当迁移到下游密集任务(如目标检测)时,随机展现出更为显著的优势。针对这一现象,我们从多个角度对随机策略的优势进行了详细分析,并确定了分组策略设计的几个关键要素:位置信息、头特征多样性、全局感受野以及固定分组模式。我们证明,只要满足这四个条件,视觉 token 仅需一种极其简单的分组策略,即可高效且有效地处理各种视觉任务。我们还在多种模态上验证了所提随机方法的有效性,包括视觉任务、点云处理以及视觉 - 语言模型。
34. TTP:面向视觉语言模型的对抗检测与鲁棒自适应的测试时填充方法
TTP: Test-Time Padding for Adversarial Detection and Robust Adaptation on Vision-Language Models
研究介绍:
视觉语言模型(如CLIP)虽在零样本识别任务中表现卓越,但极易遭受对抗扰动,在安全敏感场景下存在重大隐患。现有的训练端防御依赖高成本的对抗微调,而推理端防御又难以精准区分输入类型,导致鲁棒性与原始准确率无法兼得。针对这一痛点,本文提出了轻量化防御框架——推理时填充(Test-Time Padding, TTP)。TTP 通过对比空间填充前后CLIP特征嵌入的余弦相似度偏移,建立起跨架构、跨数据集的通用对抗检测阈值。对于检测出的对抗样本,TTP 利用可学习的填充操作修复被破坏的注意力模式,并辅以相似度感知的集成策略以强化预测;对于干净输入,则保持默认或可选集成现有自适应技术。 实验表明,TTP 在多种CLIP骨干网络与细粒度基准上均超越了现有的先进推理时防御方法,在显著提升模型抗干扰能力的同时,有效保护了原始任务的识别精度。
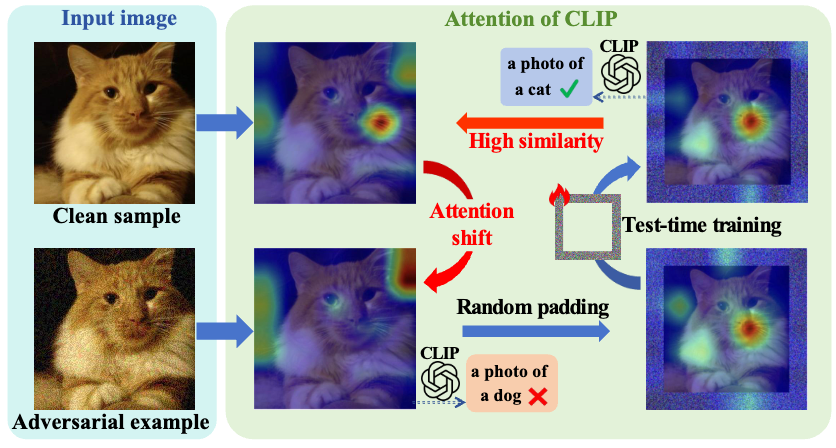
图1.干净样本、对抗扰动样本、随机填充样本以及经过可学习推理时填充(Trainable TTP)处理样本的注意力图可视化对比。对抗攻击会导致注意力机制发生显著偏移,进而引发错误预测;应用随机填充有助于恢复原始的注意力焦点,而可学习填充则能进一步将注意力精确引导至正确区域并有效抑制噪声,从而实现更准确的预测结果。
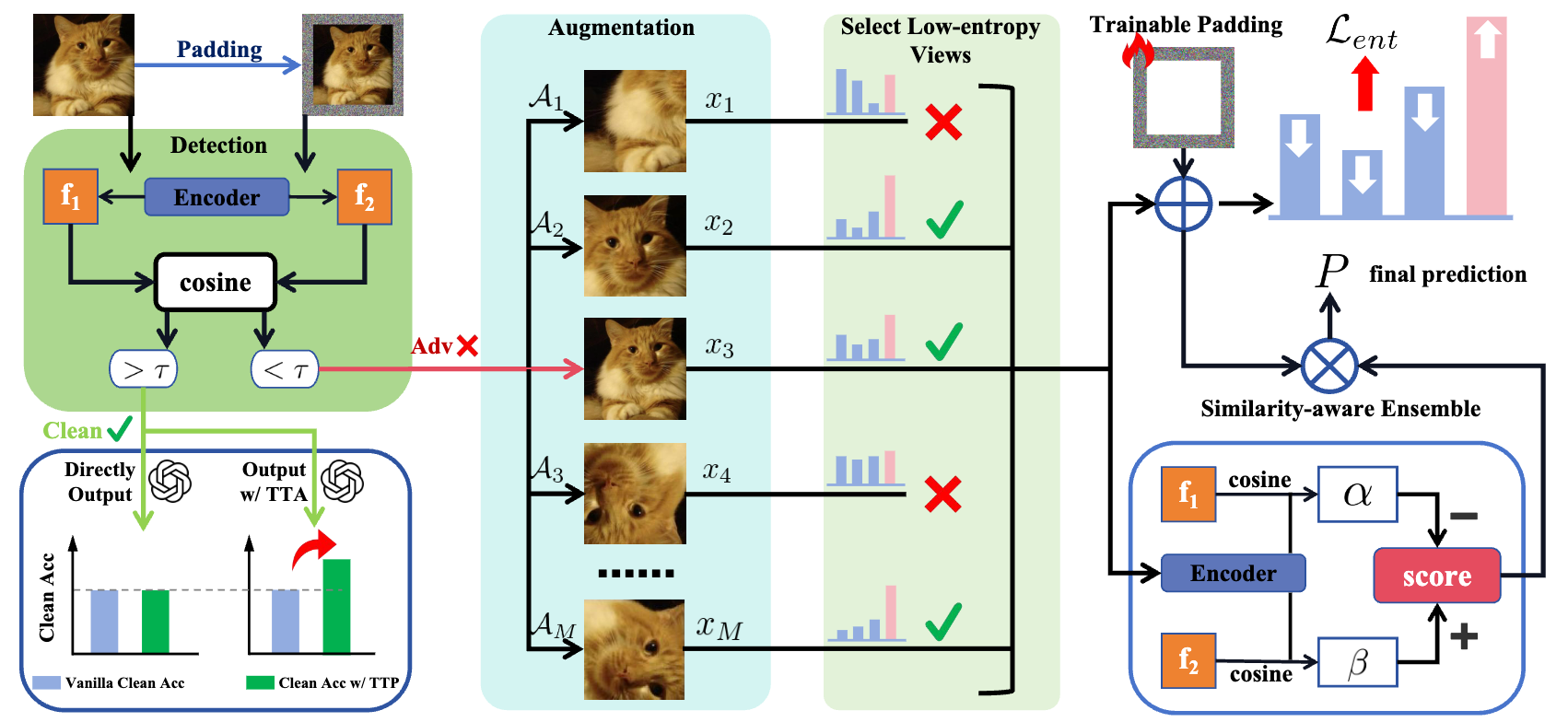
图2.所提推理时填充(TTP)流水线的概览:对于输入样本,TTP 提取应用填充前后的 CLIP 图像编码器特征,并通过对比其余弦相似度差异与通用阈值,实现干净样本与对抗样本的精准区分。干净样本无需适配直接进行识别;针对对抗样本,则激活可学习的推理时填充,利用低熵增强视图通过熵最小化策略优化填充参数。随后,相似度感知集成机制会聚合选定高置信度视图的预测结果,确保最终输出更为可靠。综上所述,TTP 实现了精确的对抗检测以及由适配驱动的鲁棒性提升。
Towards Reliable Evaluation of Adversarial Robustness for Spiking Neural Networks
研究介绍:
脉冲神经网络(SNN)通过基于脉冲的激活机制模拟大脑的高能效信息处理。然而,脉冲激活的二值性与不连续性易导致梯度消失,使基于梯度下降的对抗鲁棒性评估不可靠。尽管已有改进的代理梯度方法,其在强对抗攻击下的有效性仍不明确。本文提出一种更可靠的SNN对抗鲁棒性评估框架,从理论上分析代理梯度中的梯度消失程度,并提出自适应尖锐度代理梯度(ASSG),在攻击迭代过程中根据输入分布动态调整代理函数形状,从而提升梯度精度并缓解梯度消失问题。同时,在L∞约束下设计稳定自适应投影梯度下降攻击(SA-PGD),通过自适应步长实现不精确梯度条件下更快且稳定的收敛。大量实验表明,该方法在多种对抗训练策略、SNN结构及神经元模型上显著提升攻击成功率,实现更通用、可靠的鲁棒性评估,并揭示现有SNN的鲁棒性被明显高估,表明亟需更加可靠的对抗训练方法。
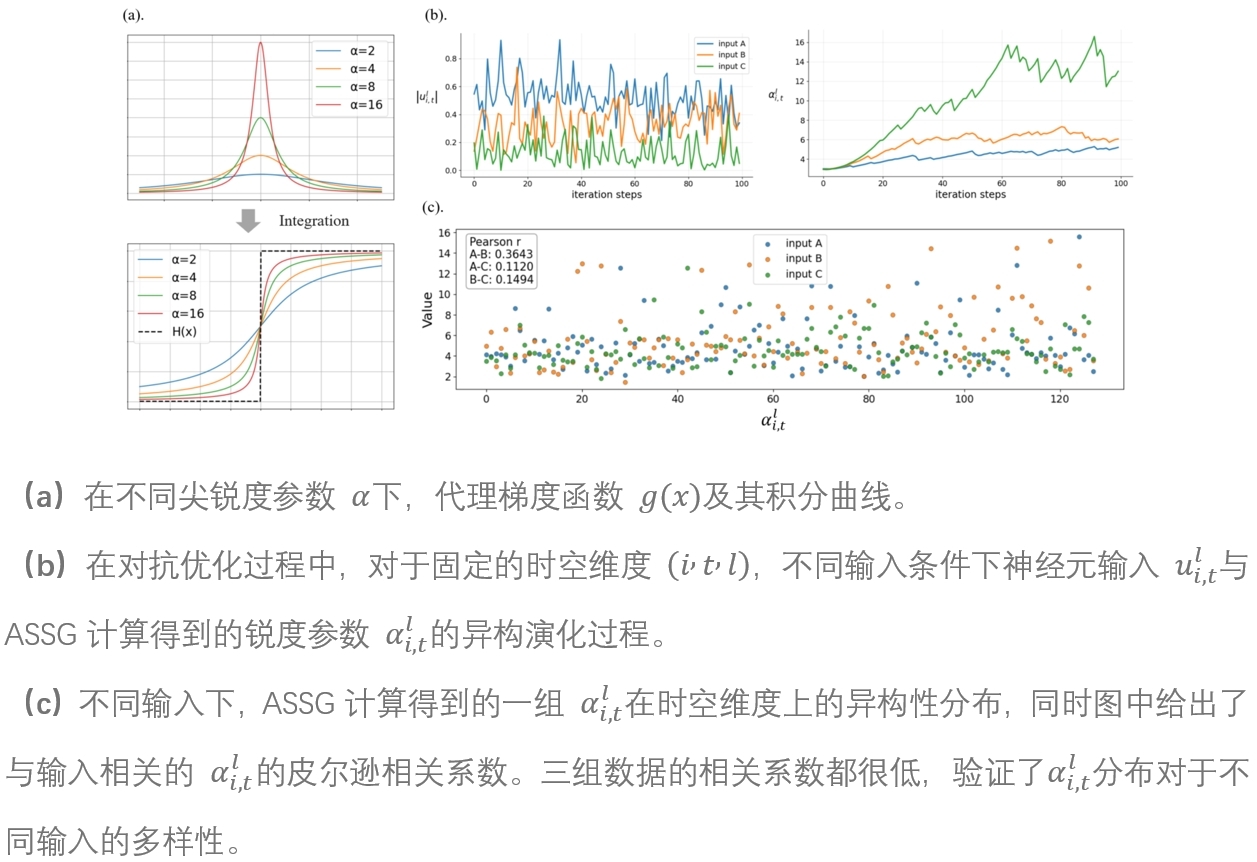
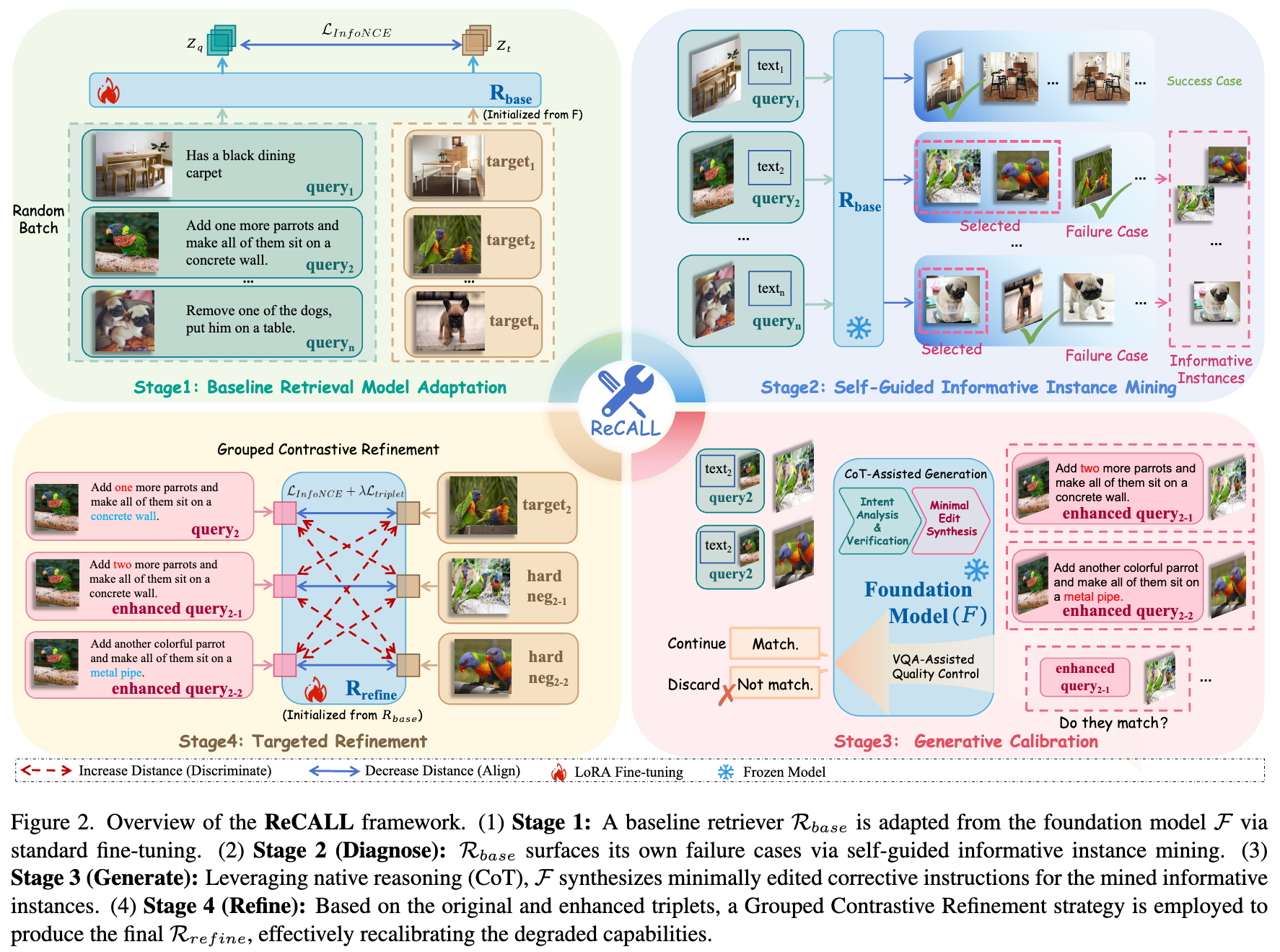
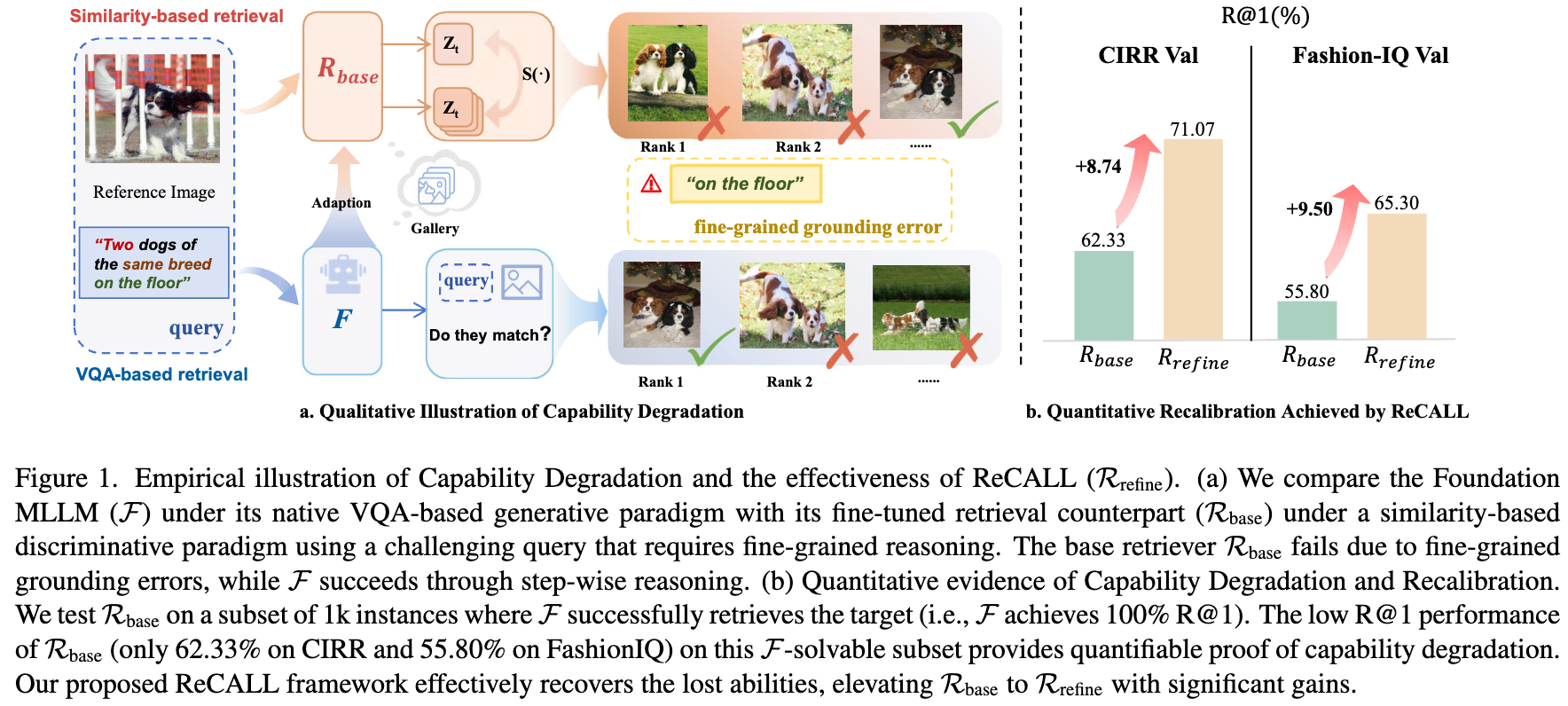
36. ReCALL:重新校准基于MLLM的组合图像检索的能力退化
ReCALL: Recalibrating Capability Degradation for MLLM-based Composed Image Retrieval
论文作者:杨天宇,何辰玮,郝祥兆,王天月,郭佳瑞,郭海云,曲磊钢,王金桥,蔡达成
研究介绍:
本文介绍了一种名为ReCALL的架构通用型新框架,旨在解决将生成式多模态大语言模型(MLLMs)应用于组合图像检索(CIR)时面临的挑战。我们在研究中发现,将生成式MLLM压缩为单一嵌入的判别式检索器会引发范式冲突,导致模型原本的细粒度推理能力发生严重的“能力退化(Capability Degradation)” 。
为了解决这一问题,ReCALL提出了一种“诊断-生成-微调”的流水线策略。首先,通过自引导的信息实例挖掘,主动诊断检索器的认知盲区。接着,利用基础MLLM生成校正指令和三元组,并引入基于VQA的一致性过滤来进行质量控制。最后,采用分组对比学习方案对这些三元组进行持续微调。这一机制使检索器能够重新内化细粒度的视觉-语义差异,并将其判别空间与MLLM内在的组合推理能力重新对齐。
实验结果表明,ReCALL在应对细粒度推理退化方面表现出色。在CIRR和FashionIQ两大基准数据集上的广泛实验显示,ReCALL均实现了SOTA(当前最佳)的性能。其中,在CIRR数据集上其R@1指标相对基线显著提升了8.38%,在FashionIQ上平均R@10达到了57.04%。这表明,通过主动生成并内化靶向校正监督信号,可以有效恢复多模态大模型的细粒度推理能力,从而实现高度可靠的组合图像检索。
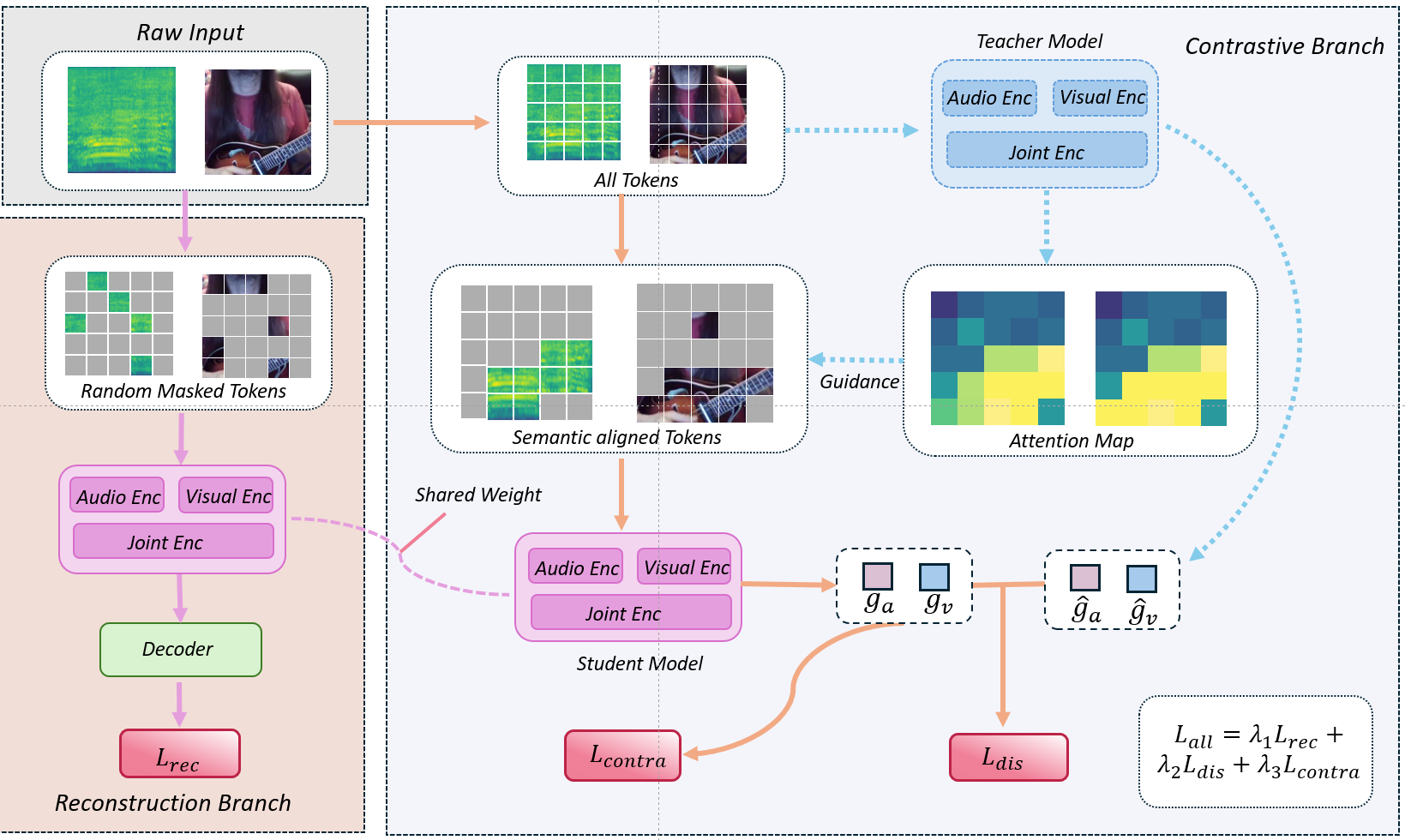
Semantic Noise Reduction via Teacher-Guided Dual-Path Audio-Visual Representation Learning
研究介绍:
当前音视频自监督表征学习的主流范式通常联合 Masked Autoencoder(MAE)与对比学习,在统一框架下进行跨模态建模。然而,真实世界中的音视频数据并非严格语义对齐:同一视频与其音频中,仅部分视觉与音频 token 承载一致的前景语义,其余多为并不对齐的语义噪声。在MAE范式的高 mask比例下,两模态 token被大幅遮挡,而对比学习仍在这一表示上施加对齐约束,容易在语义不匹配或信息不完整的特征上进行错误对齐,从而影响联合表征质量。
为此,我们对重建与对齐目标进行显式解耦,在对比学习分支中显著降低 mask 比例,以提升跨模态前景语义同时可见的概率,减少错误匹配风险。同时结合 attention-guided token 选择与 teacher–student 蒸馏机制,强化关键语义区域的对齐能力并稳定训练过程。该方法在检索与分类等下游任务上取得了显著性能提升。
38. GThinker:基于线索引导再思考的通用多模态推理方法
GThinker: Towards General Multimodal Reasoning via Cue-Guided Rethinking
论文作者:詹宇飞,吴梓恒,朱优松,薛荣坤,罗瑞璞,陈正昊,张粲,李依凡,何祯涛,杨哲铭,唐明,邱晓辰,王金桥
研究介绍:
尽管近年来多模态推理取得了显著进展,多模态大模型(MLLMs)在初始视觉感知可能具有误导性的复杂任务上仍然表现不佳。这一表现差距源于一种关键的推理缺陷,我们将其称为“视觉惯性”:尽管 MLLMs 在文本语境中擅长进行迭代式反思,但在视觉推理过程中往往不加质疑地依赖最初的视觉解释,且很少对其进行修正。
为克服这一局限,我们提出了 GThinker,一种新型具备自适应视觉再思考能力的多模态大模型。GThinker 采用线索再思考(Cue-Rethinking)机制,这一灵活的机制通过视觉线索引导推理过程,并在发现潜在不一致时主动触发对关键线索的重新审视,从而提升推理的稳健性与准确性。为赋予模型这一能力,我们设计了一个两阶段训练框架:首先通过模式引导的冷启动进行初始化,并结合评判引导的选择机制,从失败样本中学习;随后引入激励式强化学习通过多场景探索进一步优化模型行为。我们还构建了 GThinker-11k 数据集,并通过迭代式多模态标注流程支持模型训练。实验结果表明,GThinker 在 M3CoT 基准上取得 81.5% 的领先成绩,显著缓解视觉惯性问题,并在多个多模态推理任务上实现平均 2.1% 的整体提升,验证了视觉再思考机制的有效性与泛化能力。

图1.线索引导再思考机制示例图。模型根据问题和图像内容,以任意形式完成初始的推理,同时使用 <vcues_*> 标签标记出其所依赖的关键视觉线索。在初步推理链完成后,一个反思提示被触发引导模型进行再思考。随后,模型逐一回顾所有标记的视觉线索,检查其解释是否存在不一致、错误或遗漏。一旦发现问题,模型会修正或补充对该线索的理解,并基于新的理解重新进行推理,最终得出结论。
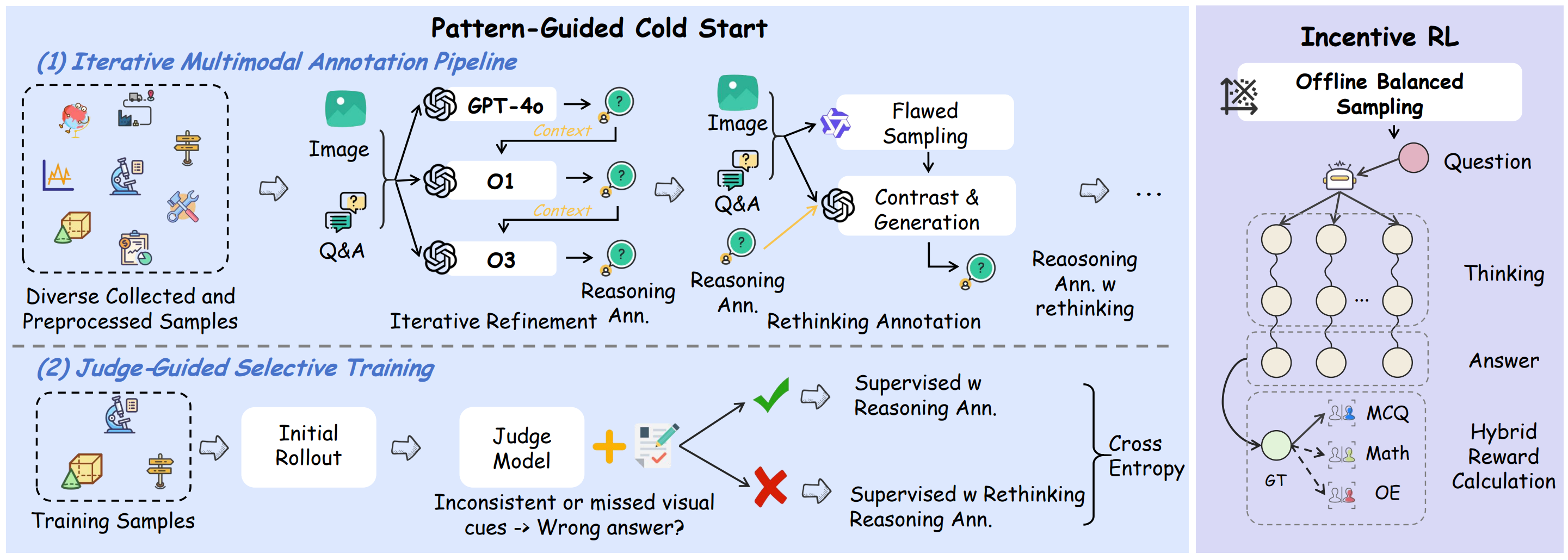
图2. GThinker训练框架。通过迭代式多模态标注流程,构建符合 Cue-Rethinking 模式的高质量推理数据。在此基础上,在模式引导冷启动阶段引入评判引导的选择性训练,教会模型如何和合适进行再思考。最后,通过结合 DAPO 的激励式强化学习,进一步提升 GThinker 在多样化场景下进行自适应、准确多模态推理的能力。
39. WISER:更广泛搜索、更深层思考与自适应融合的免训练零样本组合图像检索
WISER: Wider Search, Deeper Thinking, and Adaptive Fusion for Training-Free Zero-Shot Composed Image Retrieval
论文作者:王天月,曲磊钢,杨天宇,郝祥兆,许倚帆,郭海云,王金桥
研究介绍:
零样本组合图像检索旨在给定参考图像和修改文本的情况下检索目标图像,且无需使用标注的三元组进行训练。现有方法通常将多模态查询转换为单一模态,即生成编辑描述用于文本到图像检索,或生成编辑图像用于图像到图像检索。然而,每种范式都有其固有限制:文本到图像检索常常丢失细粒度的视觉细节,而图像到图像检索则难以处理复杂的语义修改。为了在不同查询意图下有效利用它们互补的优势,我们提出了WISER,一个无需训练的统一框架,它通过“检索-验证-优化”流程自适应整合了文本到图像检索和图像到图像检索,并显式建模了融合过程中的意图感知和不确定性感知。大量实验表明,WISER在多个基准上显著优于先前方法,在CIRCO(mAP@5)和CIRR(Recall@1)上相对于现有无需训练的方法分别实现了45%和57%的相对提升。值得注意的是,它甚至超越了许多依赖训练的方法,突显了其在多样化场景下的优越性和泛化能力。
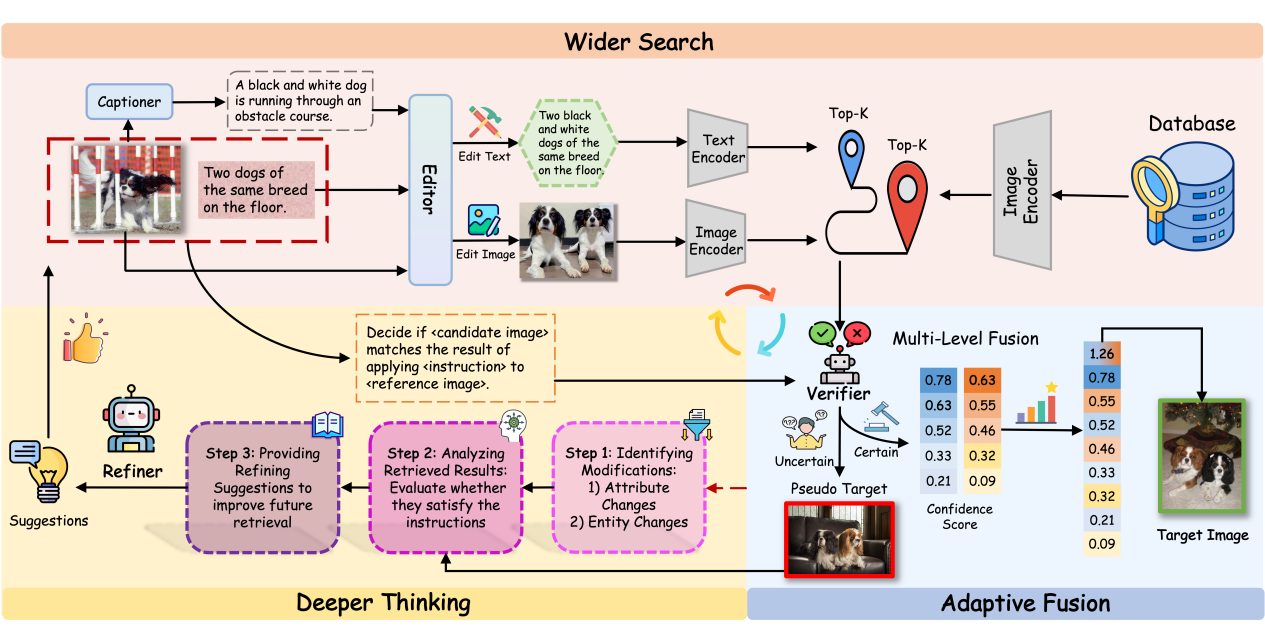
WISER 框架图。(1) 更广泛搜索:我们利用一个编辑器生成文本查询和图像查询,进行双路径检索,并将前 K 个检索结果汇总到一个统一的候选池中。(2) 自适应融合:我们采用一个验证器对候选结果进行评估,并给出置信度分数。对于高置信度结果,应用多层级融合策略;对于低置信度结果,则触发进一步的优化流程。(3) 更深层思考:针对不确定的检索结果,我们使用一个优化器分析未满足的修改需求,然后将有针对性的改进建议反馈给编辑器,进行迭代优化。
Beyond Multiple Choice: Verifiable OpenQA for Robust Vision-Language RFT
论文作者:刘业圣,李昊,徐海毓,裴宝琦,王嘉豪,赵铭轩,郑靖舒,何哲琪,姚金戈,秦博文,杨熙,张家俊
研究介绍:
本文揭示了将选择题用于 RLVR 会诱导模型产生reward hacking,损害模型在开放式问答场景上的能力。本研究通过对选项进行修改/重排/移除,量化了选择题的脆弱性。并提出将其重写为可验证的开放式问答,并使用混合的验证器以提供鲁棒、高效的奖励信号。
依托该框架,我们构建了约 20k 条高质量多模态推理数据 (图文) 数据。与使用选择题进行训练相比,我们的方法在 Qwen2.5-VL-7B与InternVL3.5-8B模型上进行训练后保持了原有的选择题性能,同时在 MMMU、EMMA 等基准上取得高于baseline 7%–10% 的性能提升,超越了一众 7B 开源视觉推理模型,验证了该框架在训练效率与泛化鲁棒性上的优势。
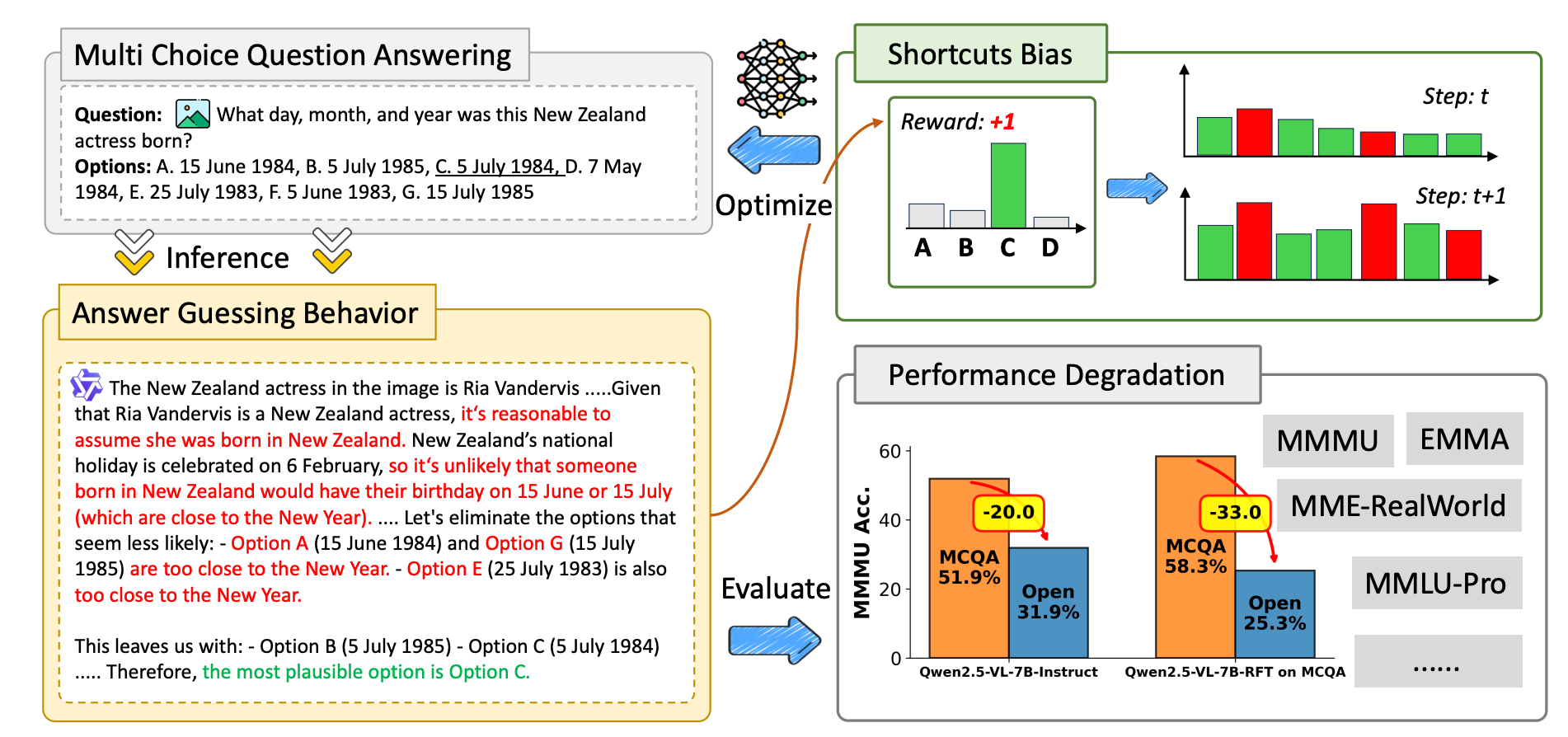
选择题数据脆弱性的示意图:左图示例展示了一个带有幻觉的推理链,模型错误地排除了干扰项却给出了正确的最终答案,从而产生了正向奖励信号。当这种正向奖励信号被用于强化学习时,会进一步放大模型的幻觉行为(右上图)。这导致模型在完成选择题与开放式问答之间的能力差距不断扩大。
OmniGen2: Towards Instruction-Aligned Multimodal Generation
论文作者:吴晨源,王嘉豪,郑鹏飞,晏瑞然,肖诗涛,罗鑫,王岳泽,李万里,蒋析言,刘业鑫,周俊杰,夏子熠,刘泽,李超凡,邓浩歌,罗坤,张博,张家俊,刘东,连德富,王鑫龙,王仲远,黄铁军,刘政
研究介绍:
多模态生成模型在处理各种模态的指令及图像生成任务中表现出色,但由于缺乏泛化性的指令对齐,其在复杂真实场景中的鲁棒性仍显不足。为此,本文提出了 OmniGen2,一个能够遵循复杂、细粒度指令的统一多模态生成模型。
本文的核心贡献是两阶段的设计方案:首先构建一个具备丰富世界知识的强大基础模型,然后使用渐进式的强化学习策略对其进行对齐。在架构上,该模型采用了解耦解码的架构以支持多样化的多模态生成,并引入了新型位置编码机制(Omni-RoPE)来提高上下文学习效率。在对齐阶段,研究团队提出了一种基于强化学习的渐进式对齐流程,通过精心调度训练任务与奖励信号(涵盖文生图、图像编辑、上下文生成),促进跨任务知识迁移,大幅增强了模型的指令遵循能力。
此外,针对现有基准的不足,本文还构建了专门用于评估上下文图像生成的基准 OmniContext。大量实验证明,OmniGen2 在文本到图像、图像编辑和上下文生成等各项任务上均展现出了卓越的语义一致性和生成质量。
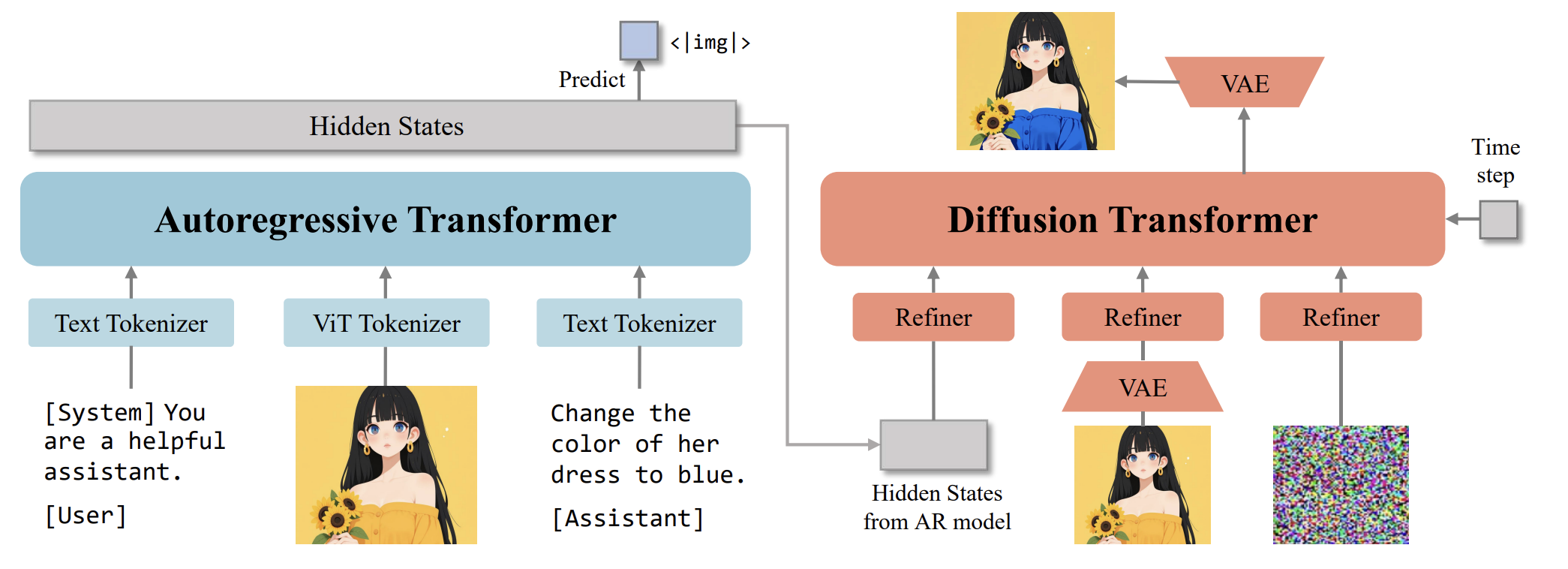
OmniGen2 的模型架构。OmniGen2 采用了独立的 Transformer 分别用于自回归和扩散任务。模型使用了两种不同的图像编码器:ViT 将图像编码后输入到文本 Transformer 中,而 VAE 则将图像编码后输入到扩散 Transformer 中。
ROSE: Rotate Your Large Language Model to See
研究介绍:
当前多模态基座模型普遍采用将视觉特征映射并拼接到输入空间的范式 。然而,这种“输入空间拼接”会大幅增加上下文长度,带来呈二次方爆炸的计算开销 。同时,由于大量视觉Token占据主导,模型在训练时易偏向视觉域,从而破坏原有的语言先验知识 。
针对上述挑战,本文提出了一种全新的视觉注入范式——ROSE 。ROSE 放弃了传统的 Token 拼接,转而将视觉语义编码为正交旋转矩阵,直接通过乘法作用于 LLM 的预训练参数上 。这种“参数空间注入”消除了对长输入序列的需求,极大节省了平方级计算开销 。此外,正交旋转操作能够保持预训练参数向量之间的相对夹角不变,从而在注入视觉语义的同时,保留了参数向量的几何拓扑结构与依赖关系。
实验证明,在12个多模态基准测试中, ROSE-7B 取得了与当前领先开源模型(如 Qwen2.5-VL-7B)相媲美的成绩 。在相近准确率下,ROSE 极大地提升了计算效率,节省了 80.7%的FLOPs 和 56.4%的推理时延。特别是在处理长视觉序列时,其计算开销依然保持平稳,展现出了卓越的长序列扩展性 。
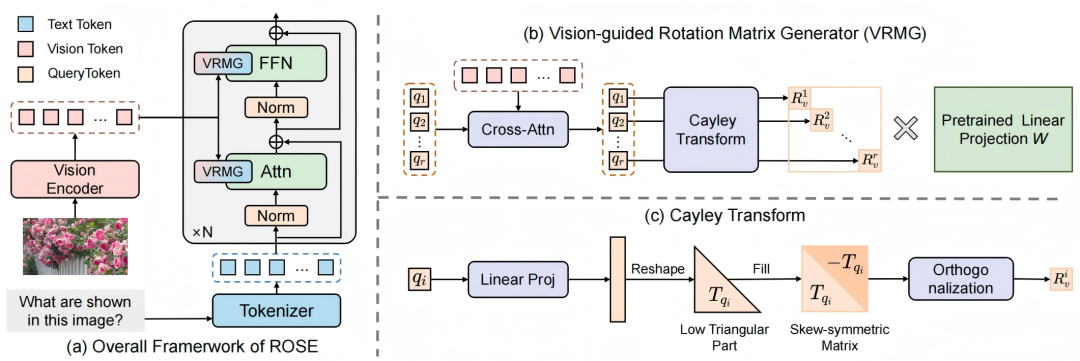
ROSE的整体框架示意图:包含视觉引导的旋转矩阵生成器(VRMG)架构及Cayley变换实现细节
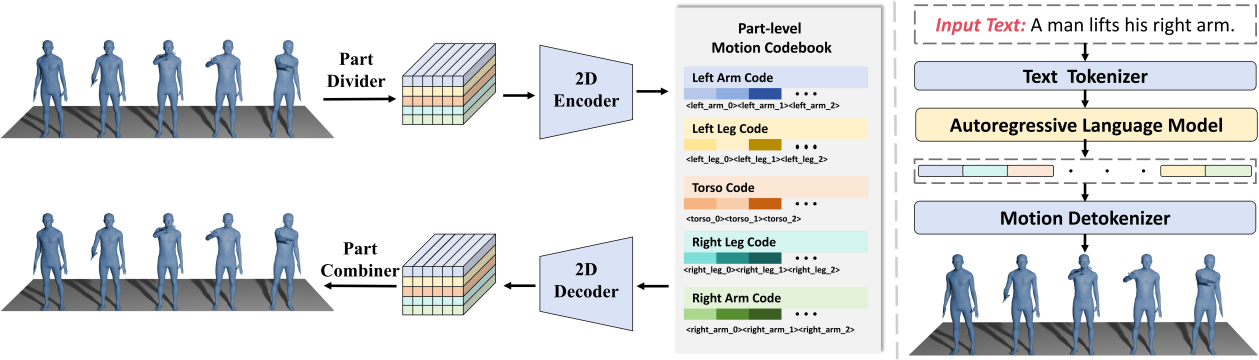
43. OpenT2M:基于开源、大规模、高质量数据的简洁动作生成方案
OpenT2M: No-frill Motion Generation with Open-source, Large-scale, High-quality Data
研究介绍:
文本驱动的人体动作生成(Text-to-motion, T2M)旨在根据文本描述生成逼真的人体运动,在动画制作与机器人领域具有广阔的应用前景。尽管近年来该领域取得一定进展,但受限于现有动作数据集规模小、多样性不足等问题,当前文本驱动的人体动作生成模型在处理未见过的文本描述时效果仍较差。为解决这一问题,本文提出 OpenT2M:一个百万级、高质量、开源的人体动作数据集,包含超过 2800 小时的人体动作数据。每条动作序列均经过物理可行性验证与多粒度过滤的严格质量把控,并配有秒级的文本标注。同时,我们搭建了一套长序列人体动作构建流程,可支持复杂动作生成任务。基于 OpenT2M,本文进一步提出 MonoFrill预训练人体动作生成模型,该模型无需复杂结构设计,即可取得优异的动作生成效果。其核心模块为 2D-PRQ,本文新提出的动作分词器,该动作分词器将人体按结构划分为不同部位,有效的捕捉时空依赖关系。实验表明,OpenT2M 可显著提升现有人体动作生成模型的泛化能力,2D-PRQ 在动作重建精度与零样本性能上均取得领先性能。
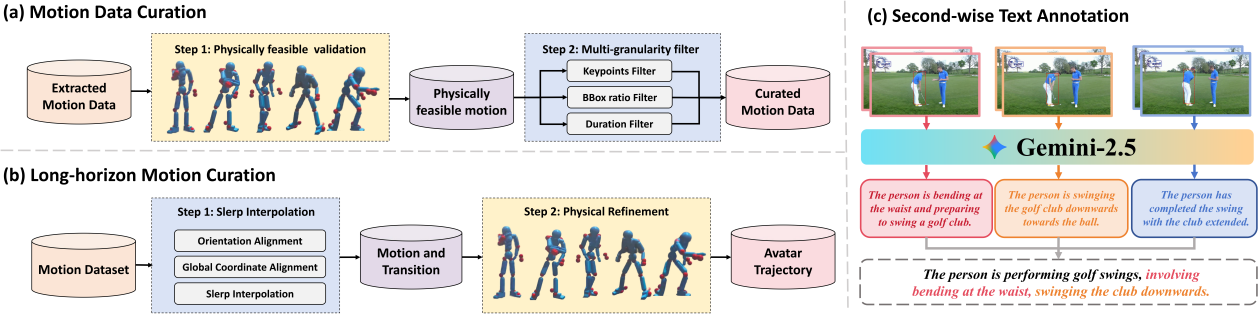
图1.数据集构建流程
Adaptive Sparsity for Efficient Long-Video Understanding
论文作者:李翰东, 刘梓康, 郭龙腾, 岳同天, 唐业鹏, 朱鑫鑫, 郑传杨, 王子铭, 王志斌, 宋俊, 屿程, 郑波, 刘静
研究介绍:
本文针对视频大语言模型(Video-LLMs)处理长视频时计算成本极其高昂的问题进行了系统性的突破。面对现有高效方法中因不可逆的信息丢弃导致细粒度感知受损,以及预设的刚性稀疏模式阻碍长程时序建模等挑战,研究团队对视频特征的时空冗余性进行了详尽的分析与重构。研究揭示了注意力机制的高度内在稀疏性与前馈神经网络对视觉 Token 的计算惯性,并引入了基于信息熵(Top-p)的上下文感知动态算力分配机制。文章提出了一种极简的自适应稀疏框架 AdaSpark,该方案仅需“自适应立方体选择注意力”和“自适应 Token 选择 FFN”两个协同组件,即可解锁视频大模型长上下文的高效处理潜力。在小时级长视频基准测试中,AdaSpark 在完整保留细粒度与长程依赖的同时,最高可降低 57% 的计算 FLOPs,性能媲美稠密基线模型,并显著优于现有高效算法。
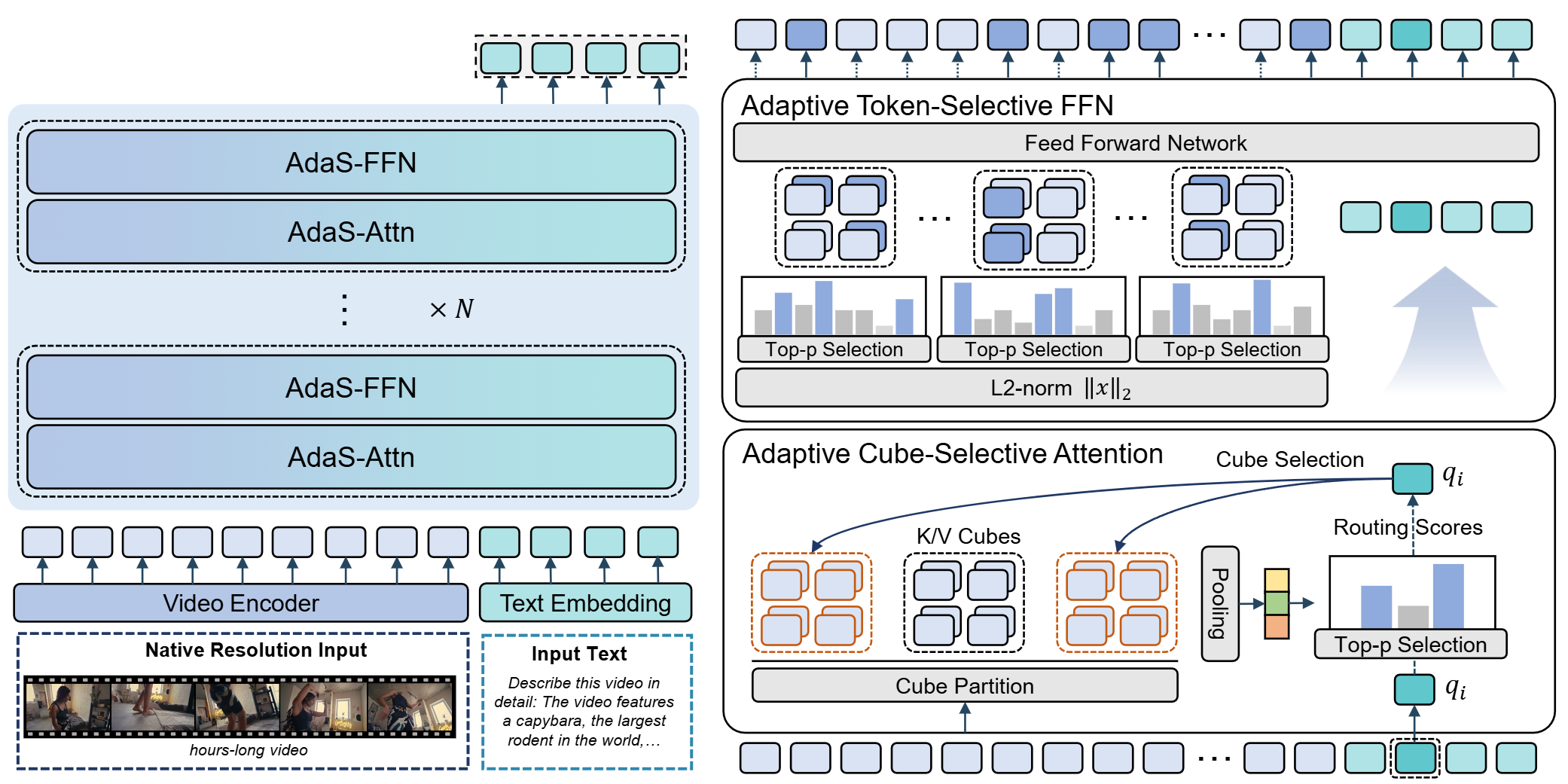
AdaSpark 框架示意图。模型以原生分辨率处理长视频并划分为视频立方体。在 AdaS-Attn 层,各 token 查询基于历史立方体的相关性得分执行自适应选择。在 AdaS-FFN 层,视觉部分 token 自适应选择通过 FFN,其余用均值补偿估计。
