近日,中国科学院自动化研究所李国齐、徐波团队提出一种神经形态脉冲大语言模型(NSLLM),通过借鉴神经科学原理,提升了大语言模型(LLMs)的能效和可解释性。此项研究不仅为高效AI的发展开辟了新方向,还为下一代神经形态芯片的设计提供了宝贵的见解。
本研究由多个国内外科研机构合作完成,包括中国科学院自动化研究所、天桥脑科学研究院尖峰智能实验室、北京智源人工智能研究院、北京中关村学院、加利福尼亚大学、清华大学、北京大学、陆兮科技、悉尼大学、香港理工大学、超威半导体公司、中国科学院大学、宁波大学等。相关研究已发表于《National Science Review》。
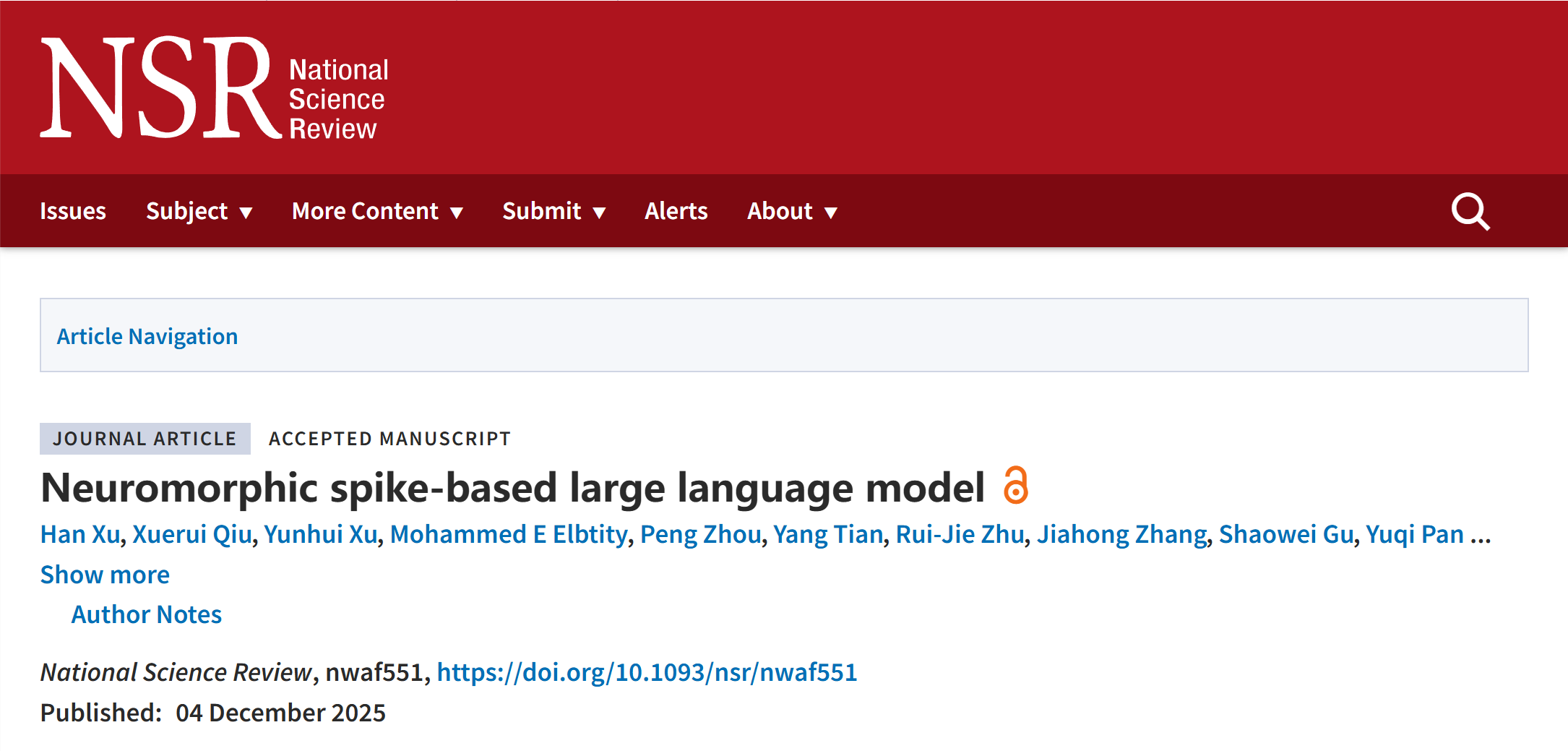
NSLLM连接大模型与神经科学
大语言模型已成为实现人工通用智能(AGI)的关键工具。然而,随着用户群体的规模扩大及使用频率增加,这些模型的部署带来了显著的计算和内存成本,限制其作为人类社会基础设施的潜力。此外,现有LLMs普遍缺乏可解释性,决策和优化过程的不透明使得其在医疗和金融等高风险领域的应用难以保证可靠性和公平性。相比之下,人脑在执行复杂任务时的功耗不足20瓦,且展现出惊人的透明度。因此,大语言模型的可持续发展与能力跃升,亟需借鉴大脑在高效能耗调控、动态认知推理与可解释性信息处理等方面的天然智慧,破解当前技术瓶颈、探寻更优发展路径。
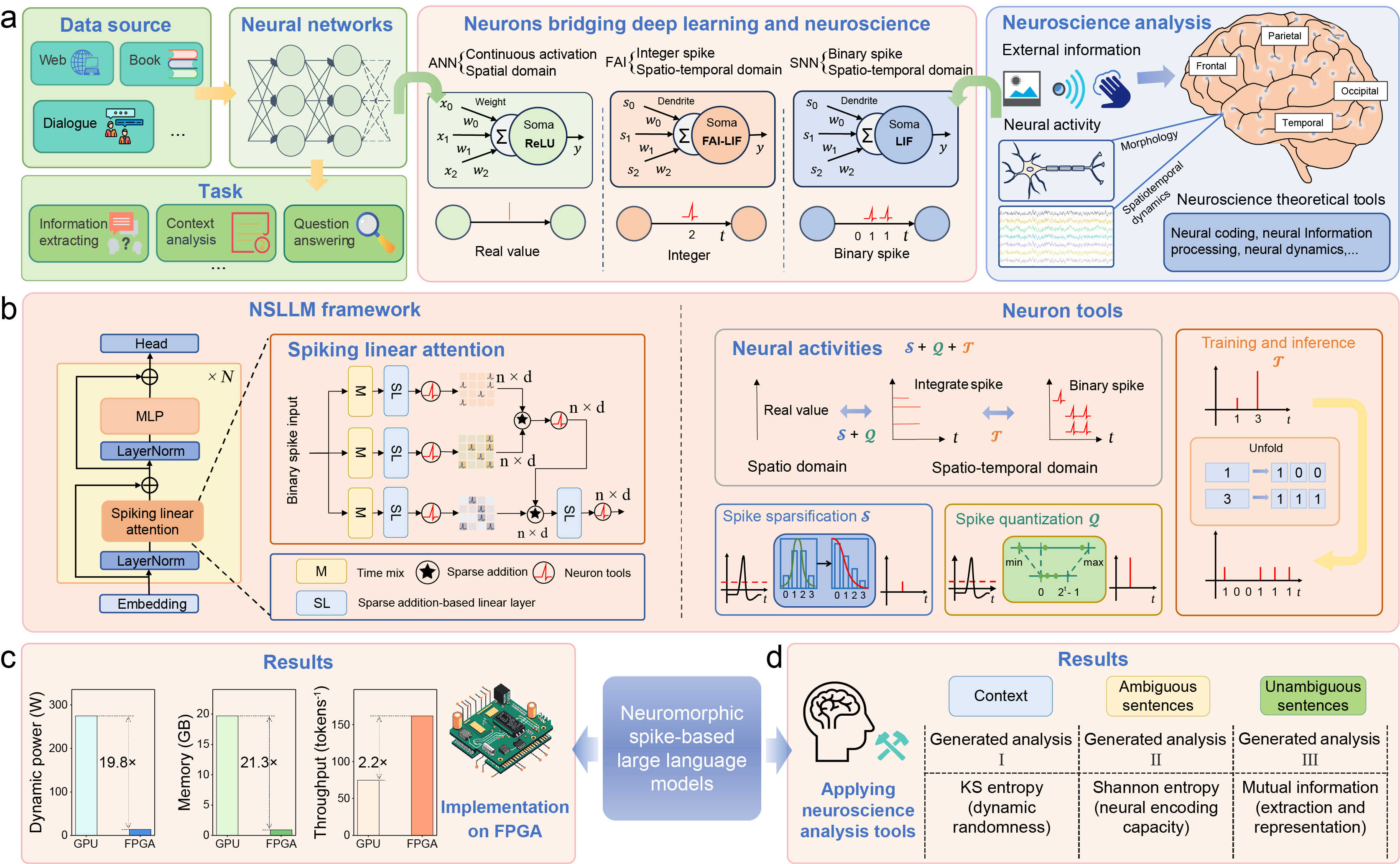
NSLLM:从大语言模型到神经形态架构的高效处理框架
超低功耗软硬协同定制MatMul-Free LLM
为验证能效,本研究在FPGA平台上定制了十亿参数量级的无矩阵乘法(MatMul-Free)计算架构。具体而言,研究团队通过逐层量化策略和层级灵敏度度量,评估层级对模型量化损失的影响,从而配置最优混合时间步脉冲模型,在低比特模型中实现了具有竞争力的性能;通过引入量化辅助稀疏策略,调整膜电位分布,下调量化映射概率,从而显著降低脉冲发放率,进一步提升模型效率。在VCK190 FPGA硬件平台上,该研究设计了MatMul-Free硬件核心,完全消除了NSLLM中的矩阵乘法操作,将动态功耗降至13.849W,吞吐量提升至161.8 token/s。与A800 GPU相比,该方法的能效、内存和推理吞吐量分别提高了19.8、21.3和2.2倍。
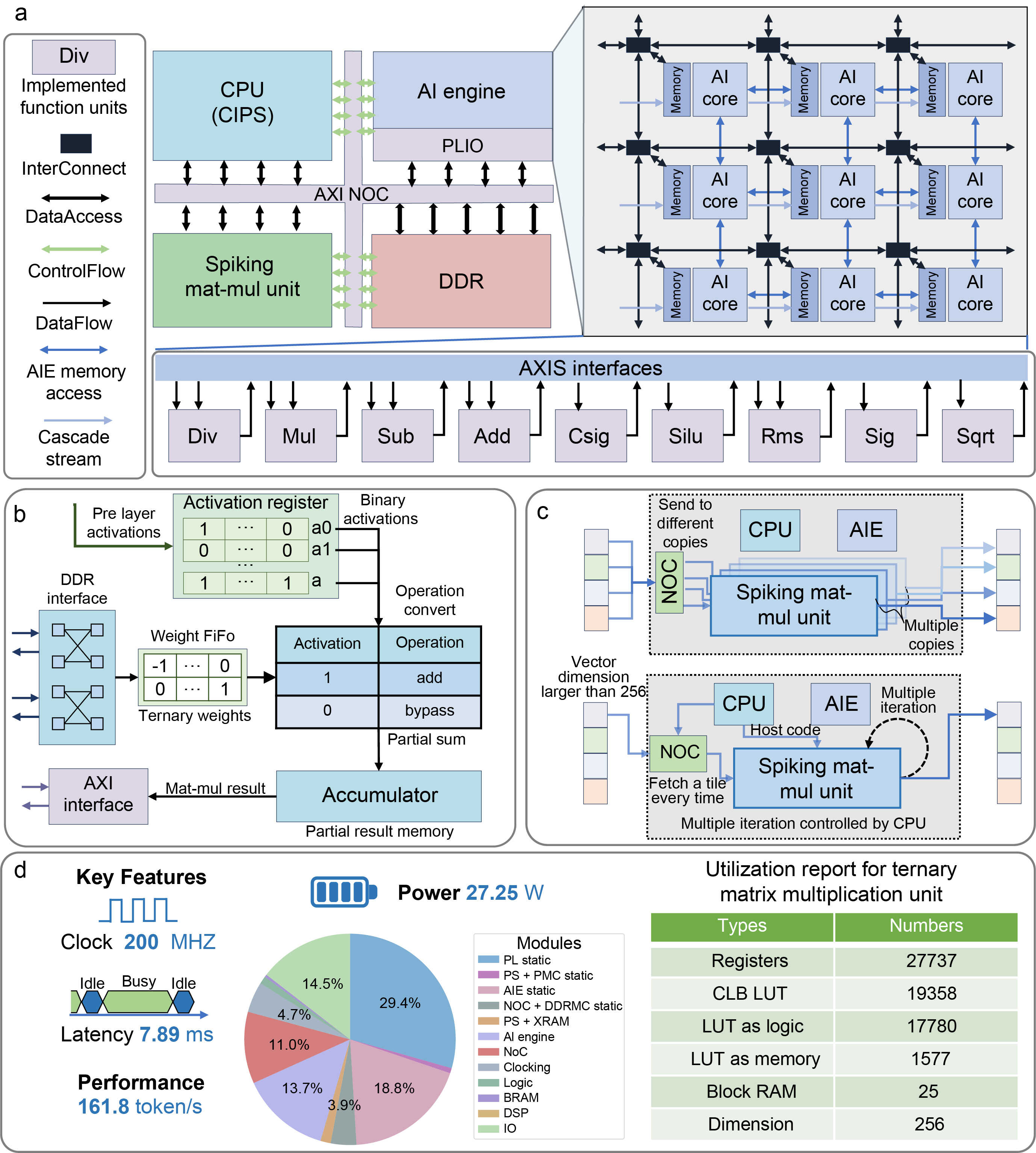
NSLLM在FPGA平台上的硬件核心设计
脉冲神经群体增强可解释性
通过NSLLM框架将LLMs的行为转化为神经动力学模型(例如,脉冲列),可以分析其神经元的动态(如通过Kolmogorov-Sinai熵度量的随机性)以及信息处理的过程(如Shannon熵和互信息)。这有助于解释NSLLM的计算角色。实验结果表明,在处理无歧义文本时,模型能够更有效地进行信息编码,从而区分含歧义文本与无歧义文本。(例如,中间层在处理含歧义文本时呈现更高的归一化互信息;AS 层表现出独特的动态特征,显示其在稀疏信息处理中的作用;FS 层的 Shannon 熵更高,表明其具备更强的信息传递能力。此外,互信息与 Shannon 熵的正相关也说明,高信息容量的层更擅长保留输入的关键信息)。因此,通过将神经动力学与信息度量相结合,该框架为LLM机制提供了生物学上可解释的见解,同时有效减少了数据需求。
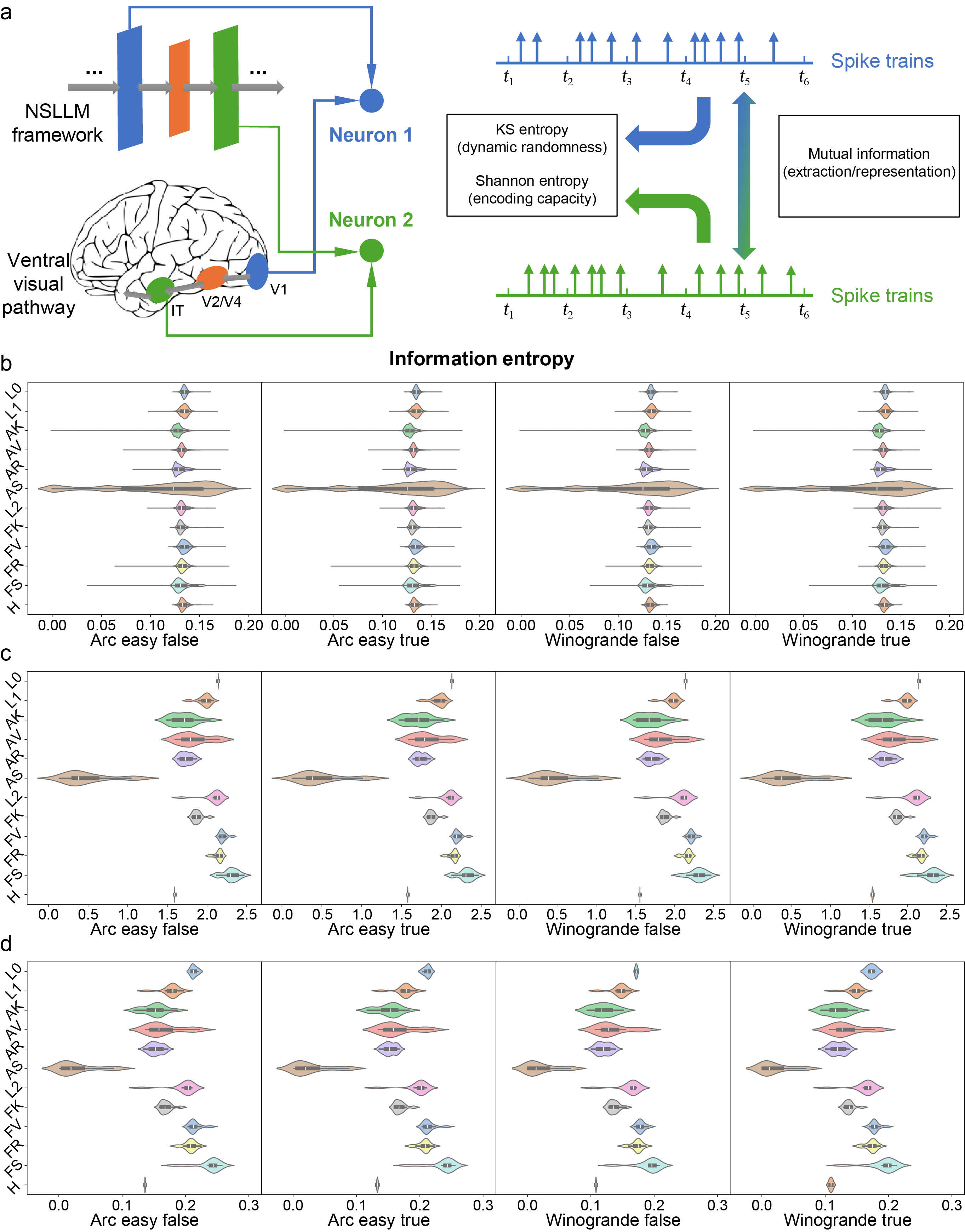
NSLLM的神经动力学分析
神经科学的研究表明,人脑通过稀疏和事件驱动计算优化能耗,促进信息传递,并增强系统的可解释性。基于这一思路,该团队构建了一个跨学科的统一框架,提出了能够替代传统 LLMs 的神经形态方案,并在常识推理以及更复杂的大模型任务中(如阅读理解、世界知识问答、数学等)保持了与主流同规模模型相当的性能表现。本研究所提出的框架不仅推动了高效AI的前沿发展,为大语言模型的可解释性提供了新视角,并为未来神经芯片的设计提供了宝贵的见解。