在人工智能深度赋能科学研究的浪潮中,如何高效、准确地将海量非结构化科学文献转化为可计算、可推理的结构化知识,已成为“人工智能+科学”亟待突破的核心问题之一。传统光学字符识别(OCR)技术虽在通用文本场景中表现成熟,但在面对科学文献——尤其是包含复杂公式符号、专业图表、多模态排版与跨学科术语的学术论文时,存在识别错误、结构逻辑丢失、输出格式单一等问题,难以支持科研自动化、知识图谱构建、智能问答等下游任务的发展。
针对这一关键挑战,中国科学院自动化研究所“AI+科学”研究团队近日正式推出新一代科学文献解析工具——磐石·科学文献解析器(S1-Parser)。该工具从底层算法出发,通过构建面向科学语义理解的多模态训练体系与强化学习机制,在公式、文本、图表等多元素协同解析上实现质的飞跃,为全球科研工作者提供真正“懂科学”的智能解析引擎。
科学文献的识别不仅是字符的还原,更是语义结构的重建。为此,团队摒弃了仅依赖通用视觉语言大模型的思路,转而构建一套专为科学文献场景量身定制的算法训练范式。其核心在于三大技术支柱:全场景覆盖的科学数据构建、多模态监督微调策略,以及面向科学文献语义的强化学习优化机制。
在数据层面,团队系统性地采集并构建了覆盖三大典型科学书写形态的训练语料:手写体、数字排版体与纸质扫描体。手写体数据涵盖不同学者的笔迹风格、连笔习惯与轻微涂改等真实场景;数字排版体数据横跨数学、物理、天文、工程、生物、计算机等多个学科,包含大量嵌套公式、特殊符号与复杂排版;纸质扫描体数据则兼顾高清与低质量样本,模拟实际扫描或拍照中可能出现的模糊、倾斜、低分辨率等情况。所有数据均经过严格去噪、标准化标注与格式对齐,并通过均衡采样策略确保模型在多样场景下的泛化能力。这一“全形态、多学科、高质量”的数据基础,为模型理解科学表达的复杂性提供了坚实支撑。
在模型训练阶段,团队采用两阶段优化策略。首先,通过多模态有监督微调,使模型初步掌握文本、公式、表格、插图等异构元素的联合表征能力。在此基础上,引入一种面向科学文献语义的梯度强化学习策略优化框架。不同于传统以字符准确率为导向的训练目标,该强化学习策略优化框架专门设计了三重科学导向的奖励信号:公式语法正确性、符号完整性与结构合理性。通过强化学习优化算法持续优化这些奖励信号,模型不仅“看得清”,更能“理解对”,生成的公式在语义层面高度可靠,可直接用于符号计算、定理验证等高阶任务。
研发团队在多个科学文献数据集上开展了系统评测,磐石·科学文献解析器在篇章级解析、公式专项识别等任务中均展现出了国际领先水平。
为了更好满足科研需求,磐石·科学文献解析器的输出不仅包含高精度的文本与公式识别结果,还支持 JSON、Markdown 等结构化格式输出,可无缝对接知识抽取、文献重排版、智能问答等下游应用。目前,磐石·科学文献解析器(V1.0)已正式开源,并作为核心组件集成于“磐石·科学基础大模型”(ScienceOne),服务全球科研社区。下一步,研究团队将持续拓展其对多模态科学内容的解析能力,并推动构建开放、协作的科学智能生态。
表1 模型篇章级文献解析能力评测结果
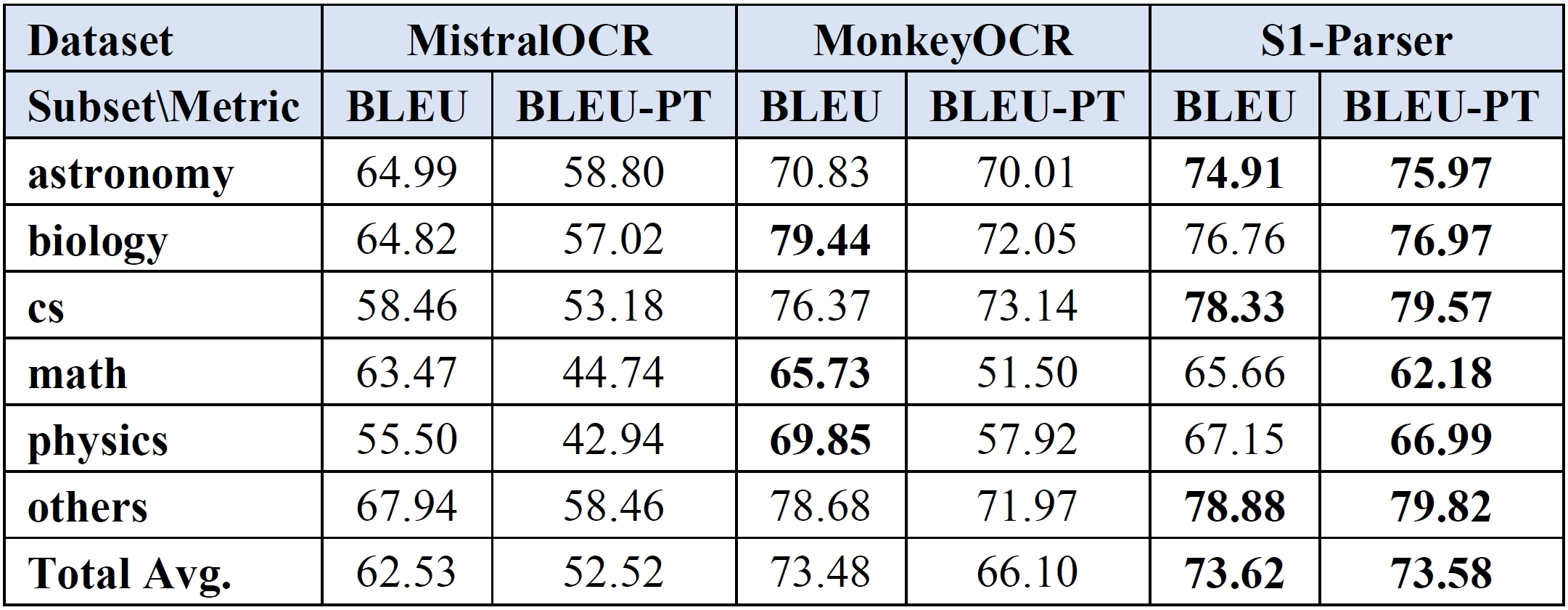
表2 模型对于科学公式解析能力评测结果
